18 KiB
+++ title="Does Aerogramme use lot of RAM?" date=2024-02-15 +++
"Will Aerogramme use lot of RAM" was the first question we asked ourselves when designing email mailboxes as an encrypted event log. This blog post tries to evaluate our design assumptions to the real world implementation, similarly to what we have done on Garage.
Methodology
Brendan Gregg, a very respected figure in the world of system performances, says that, for many reasons, ~100% of benchmarks are wrong. This benchmark will be wrong too in multiple ways:
- It will not say anything about Aerogramme performances in real world deployments
- It will not say anything about Aerogramme performances compared to other email servers
However, I pursue a very specific goal with this benchmark: validating if the assumptions we have done during the design phase, in term of compute and memory complexity, holds for real.
I will observe only two metrics: the CPU time used by the program (everything except idle and iowait based on the psutil code) - for the computing complexity - and the Resident Set Size (data held RAM) - for the memory complexity.
Testing environment
I ran all the tests on my personal computer, a Dell Inspiron 7775 with an AMD Ryzen 7 1700, 16GB of RAM, an encrypted SSD, on NixOS 23.11. The setup is made of Aerogramme (compiled in release mode) connected to a local, single node, Garage server.
Observations and graphs are done all in once thanks to the psrecord tool. I did not try to make the following values reproducible as it is more an exploration than a definitive review.
Mailbox dataset
I will use a dataset of 100 emails I have made specifically for the occasion. It contains some emails with various attachments, some emails with lots of text, emails generated by many different clients (Thunderbird, Geary, Sogo, Alps, Outlook iOS, GMail iOS, Windows Mail, Postbox, Mailbird, etc.), etc. The mbox file weighs 23MB uncompressed.
One question that arise is: how representative of a real mailbox is this dataset? While a definitive response is not possible, I compared the email sizes of this dataset to the 2 367 emails in my personal inbox. Below I plotted the empirical distribution for both my dataset and my personal inbox (note that the x axis is not linear but logarithimic).

Get the 100 emails dataset - Get the CSV used to plot this graph
We see that the curves are close together and follow the same pattern: most emails are between 1kB and 100kB, and then we have a long tail (up to 20MB in my inbox, up to 6MB in the dataset). It's not that surprising: on many places on the Internet, the limit on emails is set to 25MB. Overall I am quite satisfied by this simple dataset, even if having one or two bigger emails could make it even more representative of my real inbox...
Mailboxes with only 100 emails are not that common (mine has 2k emails...), so to emulate bigger mailboxes, I simply inject the dataset multiple times (eg. 20 times for 2k emails).
Command dataset
Having a representative mailbox is a thing, but we also need to know what are the typical commands that are sent by IMAP clients. As I have setup a test instance of Aerogramme (see my FOSDEM talk), I was able to extract 4 619 IMAP commands sent by various clients. Many of them are identical, and in the end, only 248 are truly unique. The following bar plot depicts the command distribution per command name; top is the raw count, bottom is the unique count.

Get the IMAP command log - Get the CSV used to plot this graph
First, we can handle separately some commands: LOGIN, CAPABILITY, ENABLE, SELECT, EXAMINE, CLOSE, UNSELECT, LOGOUT as they are part of a connection workflow. We do not plan on studying them directly as they will be used in all other tests.
CHECK, NOOP, IDLE, and STATUS are different approaches to detect a change in the current mailbox (or in other mailboxes in the case of STATUS), I assimilate these commands as a notification mechanism.
FETCH, SEARCH and LIST are query commands, the first two ones for emails, the last one for mailboxes. FETCH is from far the most used command (1187 occurencies) with the most variations (128 unique combination of parameters). SEARCH is also used a lot (658 occurencies, 14 unique).
APPEND, STORE, EXPUNGE, MOVE, COPY, LSUB, SUBSCRIBE, CREATE, DELETE are commands to write things: flags, emails or mailboxes. They are not used a lot but some writes are hidden in other commands (CLOSE, FETCH), and when mails arrive, they are delivered through a different protocol (LMTP) that does not appear here. In the following, we will assess that APPEND behaves more or less than a LMTP delivery.
In the following, I will keep these 3 categories: writing, notification, and query to evaluate Aerogramme's ressource usage based on command patterns observed on real IMAP commands and the provided dataset.
Write Commands
We start by the write commands as it will enable us to fill the mailboxes for the following evaluations.
I inserted the full dataset (100 emails) to 16 accounts (in other words, in the end, the server handles 1 600 emails) with APPEND. Get the Python script
Filling a mailbox
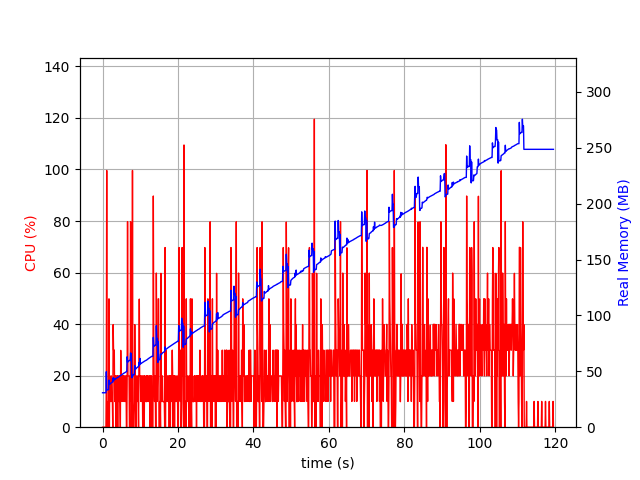
First, I observed this scary linear memory increase. It seems we are not releasing some memory, and that's an issue! I quickly suspected tokio-console of being the culprit. A quick search lead me to an issue entitled Continuous memory leak with console_subscriber #184 that confirmed my intuition. Instead of waiting for an hour or trying to tweak the retention time, I built Aerogramme without tokio console.
So in a first approach, we observed the impact of tokio console instead of our code! Still, we want to have performances as predictable as possible.
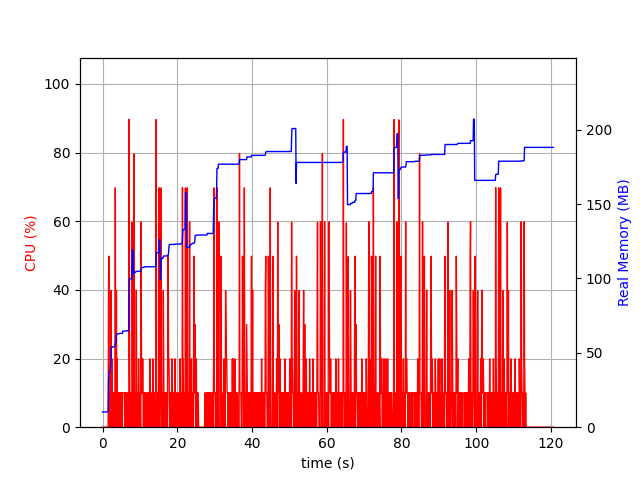
Which got us to this second pattern: a stable but high memory usage compared to previous run.
It appears I built the binary with cargo release, which creates a binary that dynamically link to the GNU libc.
The previous binary was built with our custom Nix toolchain that statically link musl libc to our binary.
In the process, we changed the allocator: it seems the GNU libc allocator allocates bigger chunks at once.
It would be wrong to conclude the musl libc allocator is more efficient: allocating and unallocating memory on the kernel side is costly, and thus it might be better for the allocator to keep some kernel allocated memory for future memory allocations that will not require system calls. This is another example of why this benchmark is wrong: we observe the memory allocated by the allocator, not the memory used by program itself.
For the next graph, I removed tokio-console and built Aerogramme with a static musl libc.
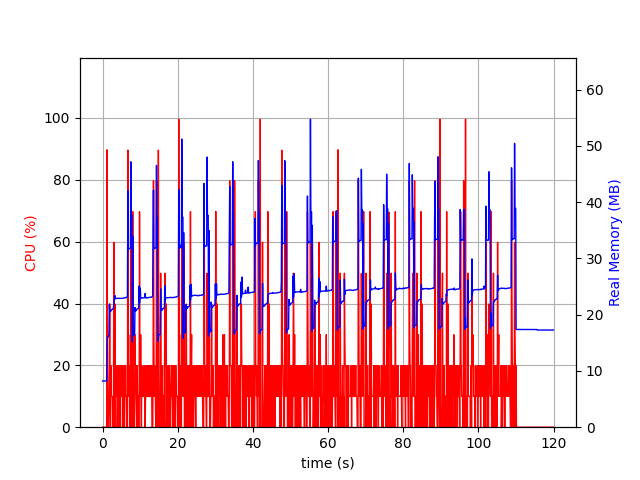
The observed patterns match way better what I was expecting. We observe 16 spikes of memory allocation, around 50MB, followed by a 25MB memory usage. In the end, we drop to ~18MB.
In this scenario, we can say that a user needs between 32MB of RAM and 7MB.
In the previous runs, we were doing the inserts sequentially. But in the real world, multiple users interact with the server at the same time. In the next run, we run the same test but in parrallel.
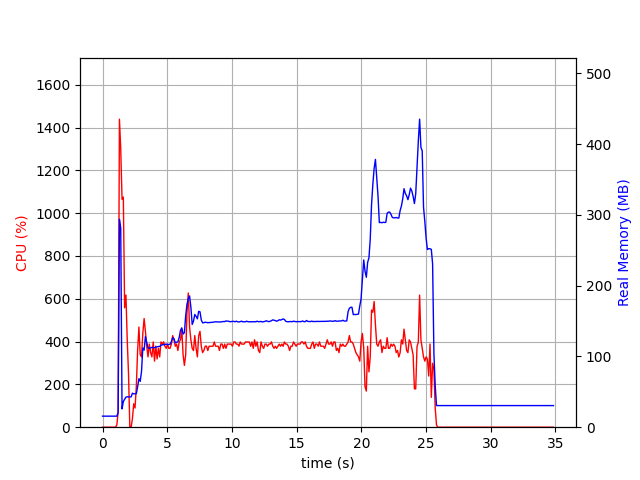
We see 2 spikes: a short one at the beggining, and a longer one at the end. The first spike is probably due to the argon2 decoding, a key derivation function that is purposedly built to be expensive in term of RAM and CPU. The second spike is due to the fact that big emails (multiple MB) are at the end of the dataset, and they are stored fully in RAM before being sent. However, our biggest email weighs 6MB, and we are running 16 threads, so we should expect around a memory usage that is around 100MB, not 400MB. This difference would be a good starting point for an investigation: we might copy a same email multiple times in RAM.
It seems that in this first test that Aerogramme is particularly sensitive to 1) login commands due to argon2 and 2) large emails.
Re-organizing your mailbox
You might need to organize your folders, copying or moving your email across your mailboxes. COPY is a standard IMAP command, MOVE is an extension. I will focus on a brutal test: copying 1k emails from the INBOX to Sent, then moving these 1k emails to Archive. Below is the graph depicting Aerogramme resource usage during this test.
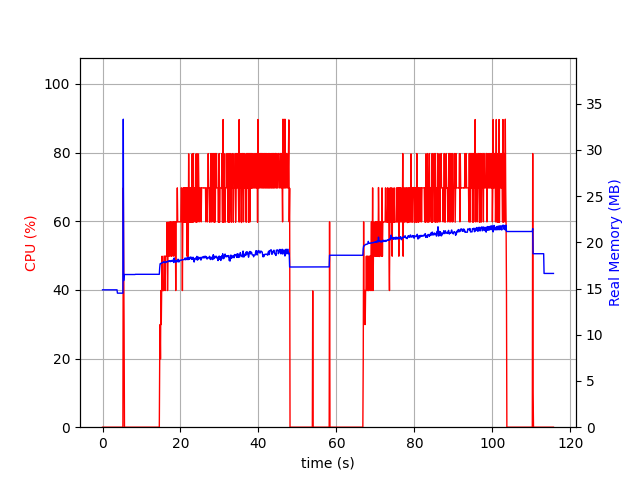
Memory usage remains stable and low (below 25MB), but the operations are CPU intensive (close to 100% for 40 seconds). Both COPY and MOVE depict the same pattern: indeed, as emails are considered immutable, Aerogramme only handle pointers in both cases and do not really copy their content.
Real world clients would probably not send such brutal commands, but would do it progressively, either one by one, or with small batches, to keep the UI responsive.
While CPU optimizations could probably be imagined, I find this behavior satisfying, especially as memory remains stable and low.
Messing with flags
Setting flags (Seen, Deleted, Answered, NonJunk, etc.) is done through the STORE command. Our run will be made in 3 parts: 1) putting one flag on one email, 2) putting 16 flags on one email, and 3) putting one flag on 1k emails. The result is depicted in the graph below.
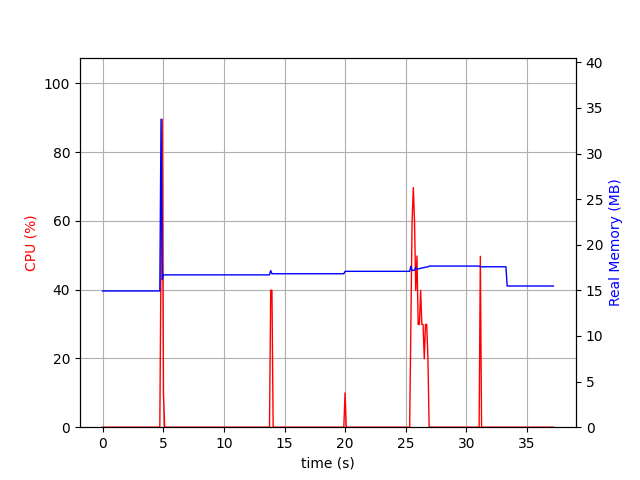
The first and last spike are due respectively to the LOGIN/SELECT and CLOSE/LOGOUT commands. We thus have 3 CPU spikes, one for each command, memory remains stable. The last command is bar far the most expensive, and indeed, it has to generate 1k events in our event log and rebuild many things in the index. However, there is no reason for the 2nd command to be less expensive than the first one except from the fact it reuses some ressources / cache entries from the first request.
Interacting with the index is really efficient in term of memory. Generating many changes lead to high CPU (and possibly lot of IO), but from our dataset we observe most changes are done on one or two emails and never on all the mailbox.
Interacting with flags should not be an issue for Aerogramme in the near future.
Notification Commands
Notification commands are expected to be run regularly in background by clients. They are particularly sensitive as they are correlated to your number of users, independently of the number of emails they receive. I split them in 2 parts: the ones that are intermittent, and like HTTP, closes the connection after being run, and the ones that are continuous, where the socket is maintained open forever.
The cost of a refresh
NOOP, CHECK, STATUS are commands that trigger a refresh of the IMAP view, and are part of the "intermittent" commands. In some ways, the SELECT and/or EXAMINE commands could also be interpreted as a notification command: a client that is configured to poll a mailbox every 15 minutes will not use the NOOP, running EXAMIME will be enough.
In our case, all these commands are similar in the sense that they load or refresh the in-memory index of the targeted mailbox. To illustrate my point, I will run SELECT, NOOP, CHECK, and STATUS on another mailbox in a row.
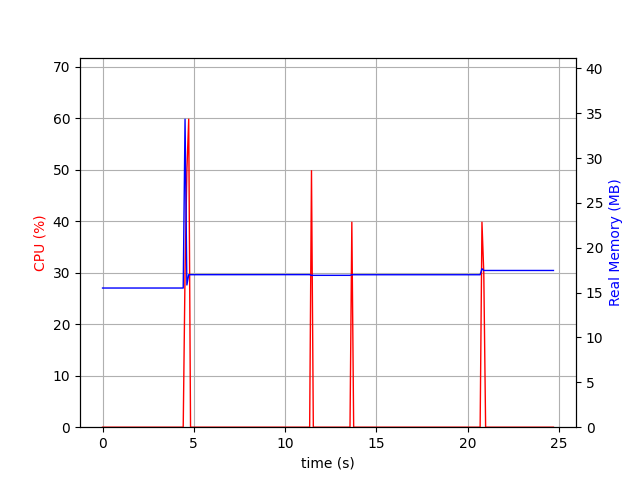
The first CPU spike is LOGIN/SELECT, the second is NOOP, the third CHECK, the last one STATUS. CPU spikes are short, memory usage is stable.
Refresh commands should not be an issue for Aerogramme in the near future.
Continuously connected clients
IDLE (and NOTIFY that is currently not implemented in Aerogramme) are commands that maintain a socket opened. These commands are sensitive, as while many protocols are one shot, and then your users spread their requests over time, with these commands, all your users are continuously connected.
In the graph below, we plot the resource usage of 16 users with a 100 emails mailbox each that log into the system, select their inbox, switch to IDLE, and then, one by one, they receive an email and are notified.
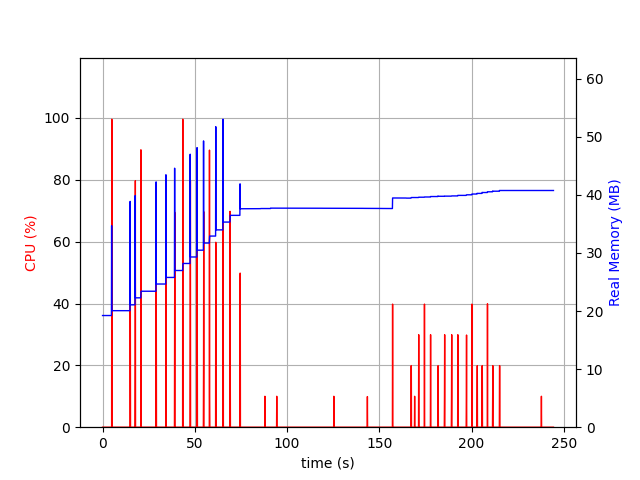
Memory usage is linear with the number of users. If we extrapolate this observation, it would imply that 1k users = 2GB of RAM.
That's not something negligible, and it should be observed closely. In the future, if it appears that's an issue, we could consider optimizations like 1) unloading the mailbox index and 2) mutualizing the notification/wake up mechanism.
Query Commands
Fetching emails
Often, IMAP clients in first instance, are only interested by email metadata. For example, the ALL keyword fetches some metadata, like flags, size, sender, recipient, etc. Ressource usage of fetching this information on 1k email is depicted below.
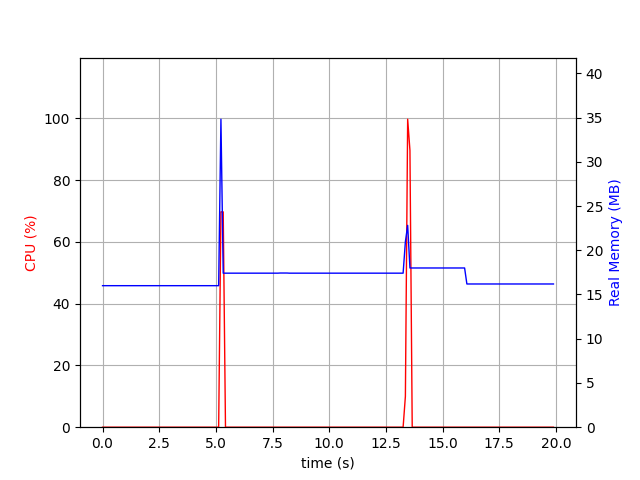
CPU spike is short, memory usage is low: nothing alarming in term of performances.
IMAP standardizes another keyword, FULL, that also returns the "shape" of a MIME email as an S-Expression. Indeed, MIME emails can be seen as a tree where each node/leaves are a "part".
In Aerogramme, this shape is - as of 2024-02-17 - not pre-computed and not save in database, and thus, the full email must be fetched and parsed.
So, when I tried to fetch this shape on 1k emails, Garage crashed:
ERROR hyper::server::tcp: accept error: No file descriptors available (os error 24)
Indeed, ulimit is set to 1024 on my machine, and apparently, I tried to open more than 1024 descriptors
for a single request... It's definitely an issue that must be fixed, but for this article,
I will increase the limit to make the request succeed.
I get the following graph.
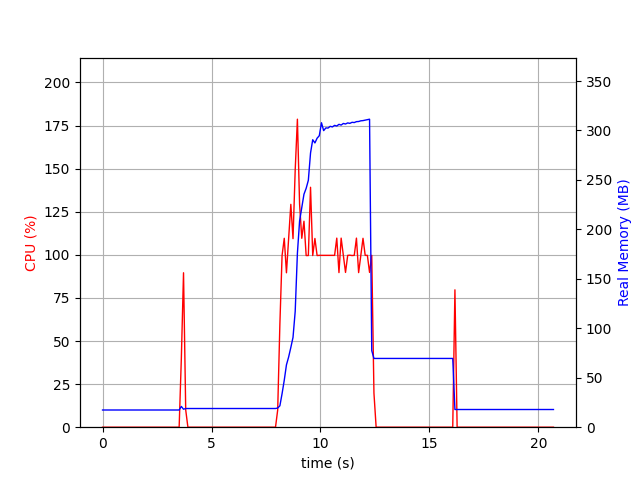
With a spike at 300MB, it's clear we are fetching the full mailbox before starting to process it. While it's a performance issue, it's also a stability/predictability issue: any user could trigger huge allocations on the server.
Searching
First, we start with a SEARCH command inspired by what we have seen in the logs on the whole mailbox, and that can be run without fetching the full email from the blob storage.
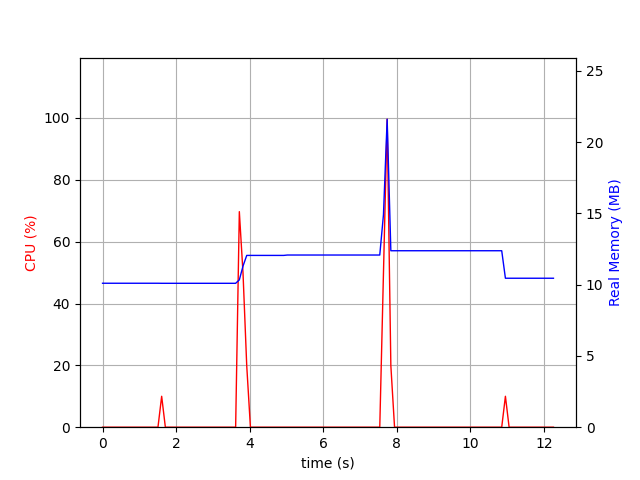
Spike order: 1) artifact, ignored, 2) login+select, 3) search, 4) logout We load ~10MB in memory to make our request that is quite fast.
But we also know that some SEARCH requests will require to fetch some content from the S3 object storage, and in this case, the profile is different.
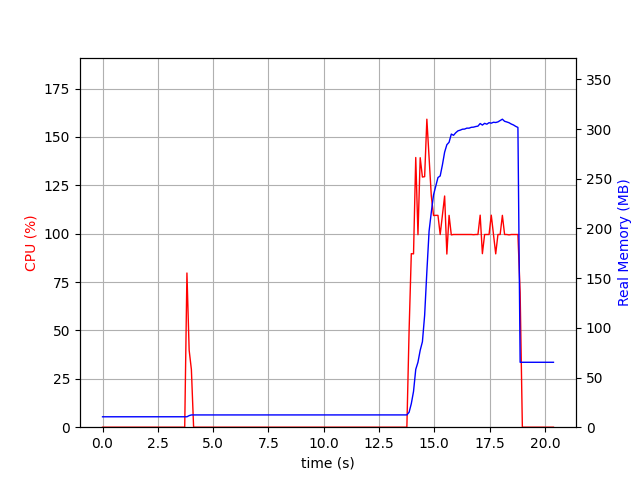
We have the same profile as FETCH FULL: a huge allocation of memory and a very CPU intensive task. The conclusion is similar to FETCH: while these commands are OK to be slow, it's not OK to allocate so much memory.
Listing mailboxes
Another object that can be queried in IMAP are mailboxes, through the LIST command. The test consists of 1) LOGIN, 2) LIST, and 3) LOGOUT done on a user account with 5 mailboxes.
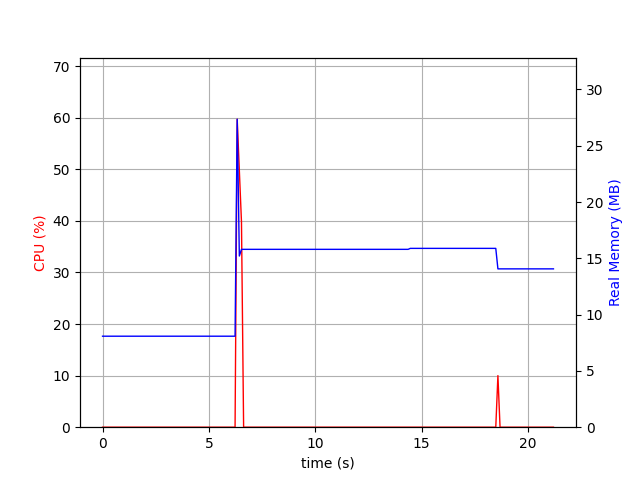
There are only 2 spikes (LOGIN and LOGOUT), as the mailbox list is loaded eagerly when the user connects. Because it's a small datastructure, it's quick to parse it, which explains why there is no CPU/memory spike for the LIST command in itself.
Discussion
TODO
Conclusion
TODO