DB error: LMDB: MDB_READERS_FULL: Environment maxreaders limit reached #660
Labels
No labels
action
check-aws
action
discussion-needed
action
for-external-contributors
action
for-newcomers
action
more-info-needed
action
need-funding
action
triage-required
kind
correctness
kind/experimental
kind
ideas
kind
improvement
kind
performance
kind
testing
kind
usability
kind
wrong-behavior
prio
critical
prio
low
scope
admin-api
scope
admin-sdk
scope
background-healing
scope
build
scope
documentation
scope
k8s
scope
layout
scope
metadata
scope
ops
scope
rpc
scope
s3-api
scope
security
scope
telemetry
No milestone
No project
No assignees
3 participants
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference: Deuxfleurs/garage#660
Loading…
Add table
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Hello, i am running garage v0.8.4 on two hw arm nodes with 64 cpu and 512 gb ram, disk layout is 6 ssd drives each 8tb mounted as raid6, overall storage size 30tb. Cluster is used only as block storage for https://github.com/thanos-io/thanos to store metrics and retrieve them on demand (prometheus like api), currently size of the bucket is
and im running into vast array of issues
Strange behavior of block_ref and sync queue, its constantly grows and never goes down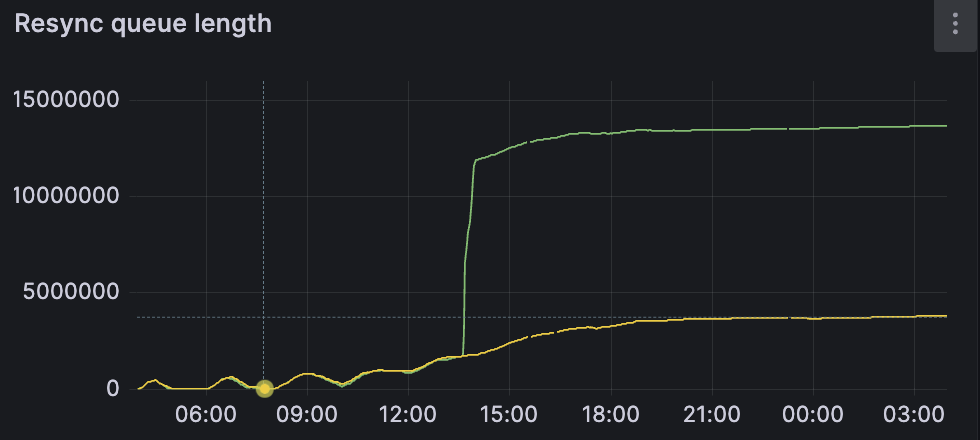
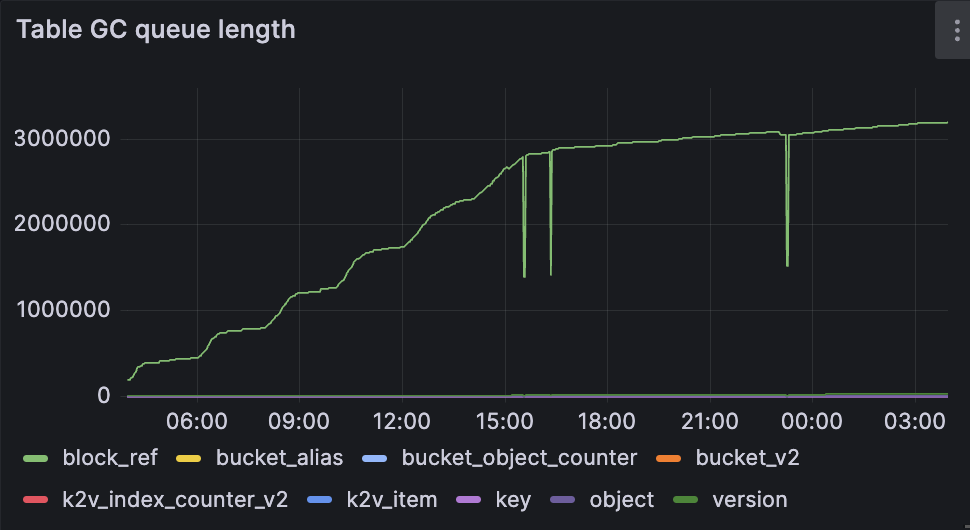
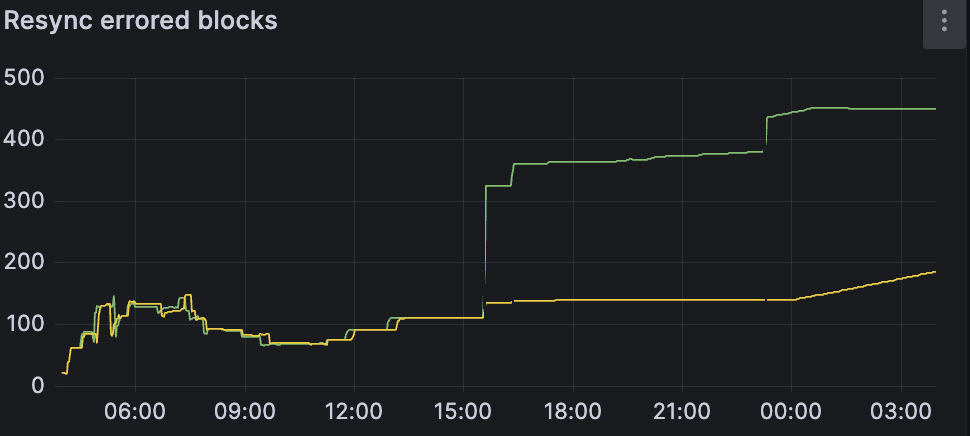
errors in log
cat /etc/garage.toml
ive tried to purge errored blocks (as it seems like actual file that block references is deleted) via garage block purge but no help
also workers seems to be quite odd
would appreciate any help regarding those issues
Updated to v0.9 but errors still occurring
also garage unit on one node failed with error
Congrats, I think you've probably put the most load on a Garage cluster than I have ever seen. You are definitely in uncharted territory here, and it is to be expected that things could break.
You seem to be having at least the following issues:
DB error: LMDB: MDB_READERS_FULL: Environment maxreaders limit reached: this means you are doing too many concurrent requests compared to the current configuration of your Garage node. Each requests may need to aquire one (or several) "reader slot" in the LMDB DB, among a fixed pool of available slots. The size of the pool is defined here. Your options are: send fewer requests; change the value to a bigger value and recompile Garage; make a PR that allows this value to be changed in the garage.toml config file (please do it if you have the time!). This is the very first thing you need to fix, Garage works under the expectation that the DB engine can be relied upon at all times, which is not the case here.Your resync queue contains way too many items, did you call
garage repair blocksseveral times without waiting for the queue to be drained? I see you are using a block size of 100MB and you have about 5TB of data, so you should have of the order of 50-100k blocks, not 10M.INFO garage_api::generic_server: Response: error 400 Bad Request, Bad request: Part number 2 has already been uploaded: I think this one will stop appearing with Garage v0.9For further investigation, please show also the output of:
garage block list-errorsgarage stats -aThe following is not an issue:
Concerning your second message with a stack trace, this looks like it could be a logic bug in Garage code. Could you open a separate issue to discuss it?
Hello, thank you for a swift response, after update to v0.9 i couldnt get rid of 500x errors and partial uploads, also i had no incoming traffic for some reason, ive deleted meta and data folders (basically purged whole cluster and reenabled it from the start), so far i have no errors for api, and no lmdb errors (ive decreased concurrency in thanos also) the only thing im concerned about is resync queue, also ive set block size back to 10mb
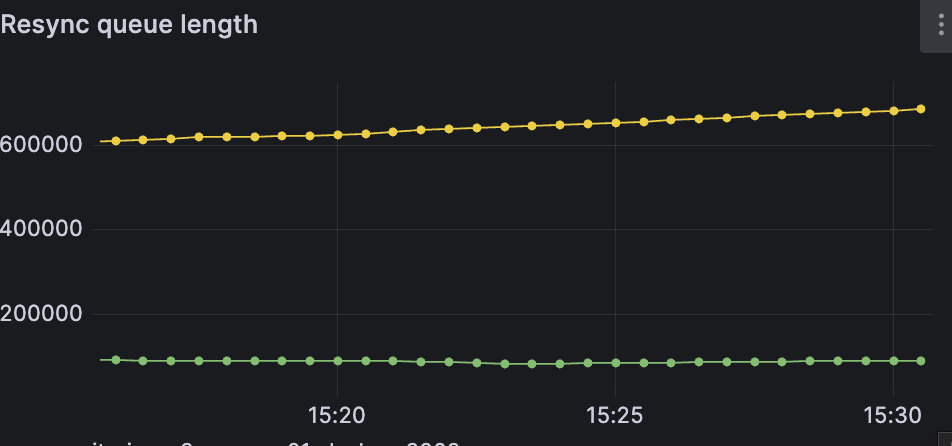
output of garage stats -a, errors are empty due to reinit
Generally speaking is there any guidelines on how to scale garage for storing large quantities of files optimized for read/write performance?
For the resync queue, definitely do the following:
Thank you queue did start to decrease rapidly
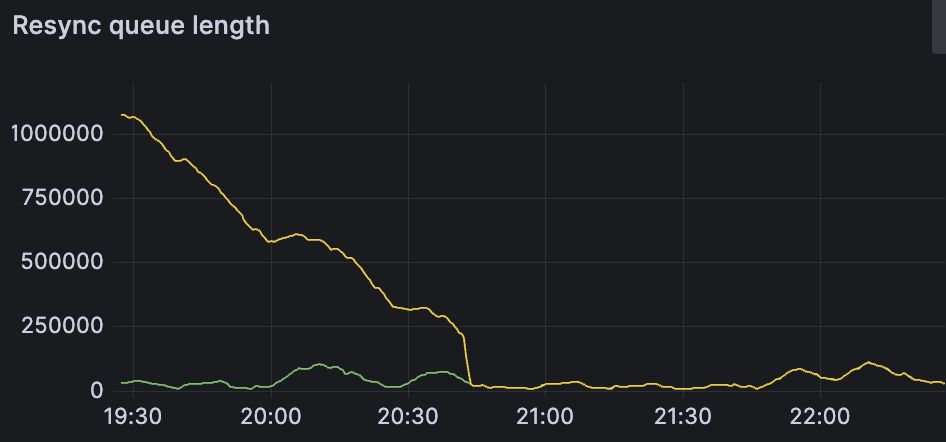
i cannot reproduce this error now, i think it was related to setting block size too high, it was to 512mb at that point as i was trying to figure out what could be the problem
ive also noticed some strange (as it seems at this point) behavior regarding memory consumption
looks like garage tries to cache all memory available on the node itself, but maybe its expected
The caching behavior is normal, it is not Garage but your kernel that is keeping everything in cache. Things that are in cache can be evicted when the memory is necessary for actually running programs, but as long as it is not required the cache just stays there because it has a probability of helping accelerate future disk access. This is 100% normal for Linux.
after few days of being stable, one of the thanos components decided to restart and resync blocks stored on s3 (10.1 tb) which increased read operations and basically made cluster read only as all the write operations failed with 503 error, unfortunately i couldnt find anything suspicious in logs, it looks like operations are working as expected but theres no write requests
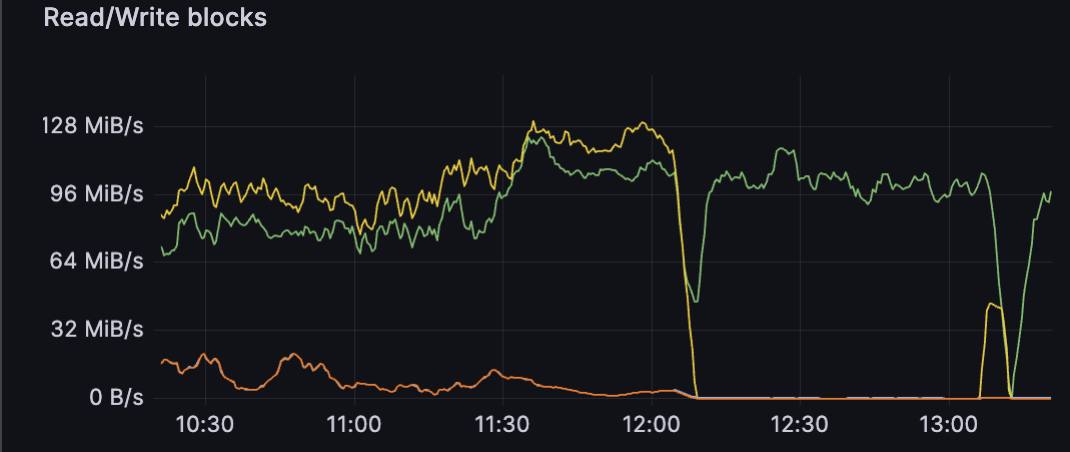
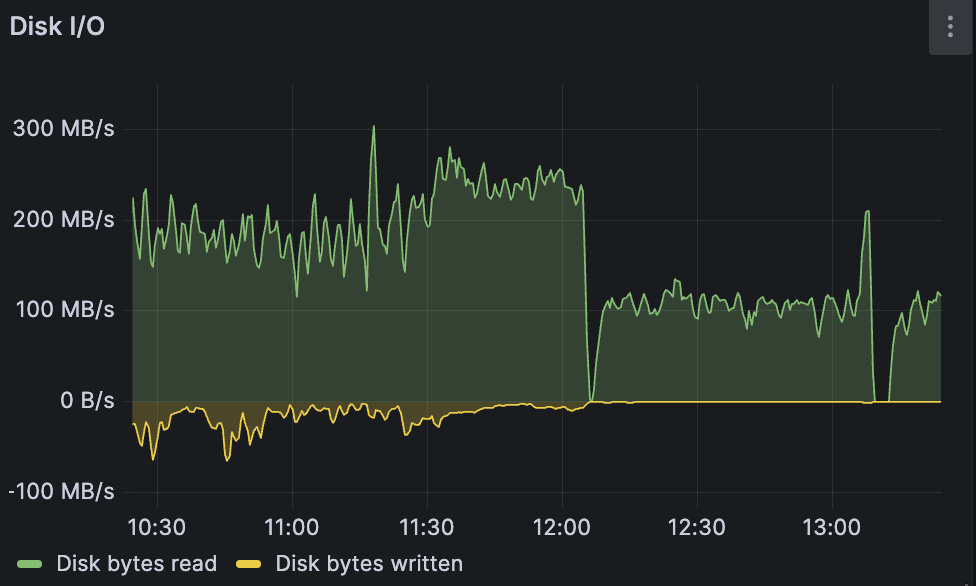
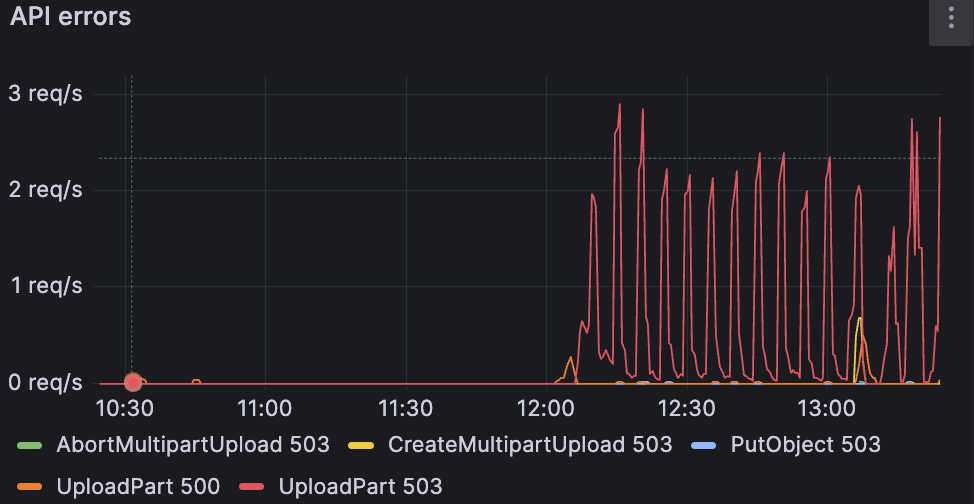
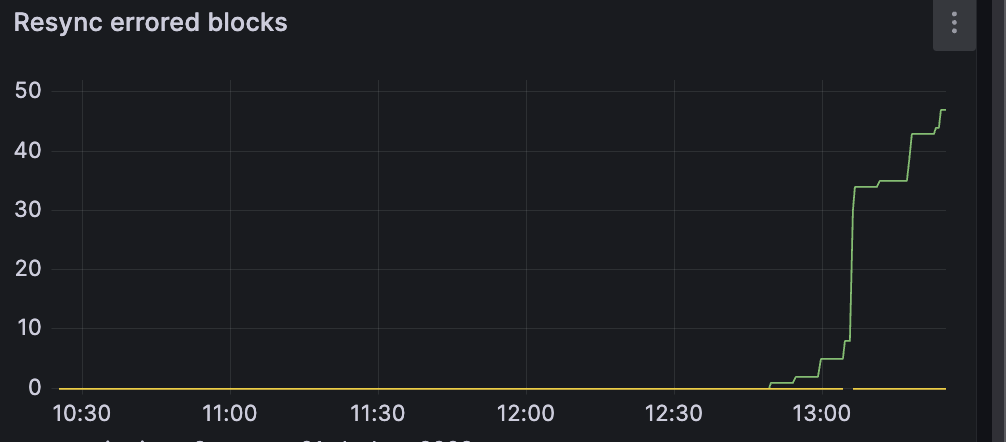
also looks like cluster is out of sync again
found an error looks like one node is down but it availiable via icmp and garage process is up
After few attempts to restore it i decided to drop data again and reinit with multiple disks
after reinit seems like cluster is not working at all, 503 errors on upload and
errors in log
So ive reinited previous configuration, with raid6 but tuned parameters a bit
for raid ive set
and also i had some errors in dmesg
ive tried to tacke it by setting
but no luck
probably its not possible to make it work for such high load( but anyway looks quite good and easy to operate if you dont have large amount of data and you dont query it constantly
Hey, as a big user of LMDB/Heed myself, I can say that we already encountered the issue at meilisearch and ended up increasing the value to 1024 on our side.
It doesn't seem to have a big impact on performances, so I guess the default value could be way higher than 500. See: https://web.archive.org/web/20200112155415/https://twitter.com/armon/status/534867803426533376
@tamo thanks for the feedback, we'll consider increasing the reader count to at least 1024