Unbounded block buffering, was: nomad (lmdb / sqlite): inevitable OOM #788
Labels
No labels
action
check-aws
action
discussion-needed
action
for-external-contributors
action
for-newcomers
action
more-info-needed
action
need-funding
action
triage-required
kind
correctness
kind/experimental
kind
ideas
kind
improvement
kind
performance
kind
testing
kind
usability
kind
wrong-behavior
prio
critical
prio
low
scope
admin-api
scope
admin-sdk
scope
background-healing
scope
build
scope
documentation
scope
k8s
scope
layout
scope
metadata
scope
ops
scope
rpc
scope
s3-api
scope
security
scope
telemetry
No milestone
No project
No assignees
2 participants
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference: Deuxfleurs/garage#788
Loading…
Add table
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Hello there! I'm using Nomad on Debian 12 to run a three-node garage cluster (v0.9.3), and
rcloneto interact with the S3 API. Setup was generally a breeze and everything seems to run smoothly.When I go on to perform my first bulk upload, however, garage will start gobbling up memory until the process is inevitably OOM killed by the Nomad scheduler. There are no errors in the logs.
Yes, I am running Nomad with memory oversubscription enabled, but it doesn't seem to matter how much memory I assign in the
memory_maxparameter: usage will climb and climb until the OOM hammer falls. I stopped trying at 4096 MB.Now, my initial attempts were with the LMDB engine, about which, as my troubleshooting began, I found some similar reports (e.g. #439, #509, #517, #681). So I went on to rebuild the cluster with the SQLite backend instead. The results, however, were the same: I'd start an upload process and watch the memory usage climb until garage is OOM killed.
The upload process in question looks like this:
rclone copy large-dir garage:cld/large-dir --progress --transfers 16 --fast-listHere
large-diris 38 GB worth of files in the 5–10 MB range. I tried experimenting with the--transfersflag (smaller values, omitting it entirely), no--fast-list, etc. but nothing of this seems to make a difference.The
rclonebackend is defined as follows:This is the Nomad job definition:
And the
garage.toml.tpl(which is verified to render correct values in the Nomad job):Output of
garage status:And of
garage layout show:Hello, thanks for the bug report.
Generally Garage uses a reasonable amount of RAM, it does not grow infinitely when requests are submitted. The behavior you are seeing is anormal and unexpected. Unfortunately, I don't know where this can come from and I don't see anything wrong in your setup.
The next steps to debug this are:
check for anything wierd in the logs
use a development build with profiling tools / instrumentation to try to figure out what is going on
Very strange indeed. The Nomad cluster in which I'm deploying Garage has been chugging along fine for a long time, running some 50+ allocations without issue. Given the resource isolation of Nomad jobs, I can't think of anything that would affect the environment running Garage other than what you see here.
Nothing weird in the logs, and no block errors or anything of the kind.
Before diving into development builds, I'll try to find some time to redeploy on bare-metal to exclude the possibility that it's related to the resource allocations and so forth inherent to Nomad and Docker.
I redeployed on bare metal with an identical configuration and made some interesting findings. The excessive memory usage does in fact occur, same as in the Nomad environment, but it seems this is specific to upload jobs handling certain types of files. Let me illustrate what I mean.
One the one hand, here is the memory usage of the Garage process during 4 minutes of uploading a directory containing ~40 000 small files (mostly
webpandjpegthumbnails):rclone copy thumb-dir garage:cld/thumb-dir --progress --fast-list --transfers 8The values represent memory usage in MB, captured every 30 seconds. As you can see, no problems here.
On the other hand, here is the memory usage during 4 minutes of uploading my initial test directory of ~5000 files in the 5–10 MB range (mostly
mp3files):rclone copy mp3-dir garage:cld/mp3-dir --progress --fast-list --transfers 8And on it goes until I stop the upload. I don't quite know what to make of this since, as you said, this is unexpected behaviour, but I figured I might as well include my findings here.
Ok, so I think I know what is going on, and this is indeed a bug in Garage. I suppose one of your nodes has a slower internet connection, and you are expecting it to receive copies of your objects asynchronously? Currently, the node that is receiving your put object requests is able to store the data fast locally and on one of the other nodes, but since it wants to make three copies in total it also keeps the data blocks buffered in RAM to send them to the third node. Unfortunately, the third node cannot receive data as fast and so this buffered data grows unboundedly. I don't know if rclone has an option to limit the upload speed but if it does you could try that, by limiting the speed to the speed of your slowest internet link.
I think we want to solve this issue in Garage, and basically there would be two strategies to do so:
allow to buffer a certain number of pending writes, but when a limit of RAM consumption is attained, reduce the speed at which we receive data from the client to apply backpressure
store all blocks as fast as possible on the local node and the one with a fast internet connection, and don't keep outstanding requests to the third node, just use an on-disk queue to transfer the data fully asynchronously
Which option would be the closest to what you would expect of Garage?
I think the downside of the second option is that the third nodes risks to never be able to catch up if too much data is coming into the cluster continuously.
nomad (lmdb / sqlite): inevitable OOMto Unbounded block buffering, was: nomad (lmdb / sqlite): inevitable OOMI'm glad we're approaching a diagnosis. Of the two strategies you mention, I would agree that the first one sounds safer.
I'm not quite sure what you mean by this. My understanding of
replication_mode = "3"(which is what my cluster is configured with) was that write operations need to complete on all three nodes before continuing, but perhaps I got that wrong. The only reference to asynchronous writes that I can find in the documentation refers toreplication_mode = "2-dangerous".In any case, I made an initial quick test with the
rcloneflag--bwlimitset to10M:10M(limiting up/down bandwidth to 10 MiB/s), but this seems to have made no difference, despite my slowest internet link being 200 Mbit/s which should be well more than enough. I stopped the upload at 1,250 MB RAM usage and noticed that, several minutes later, Garage would still sit at that level of memory usage—on all three nodes, not just the one receiving PUT requests.I then tested with
--bwlimitset to1M:1M, and now, finally, memory usage seems to be in check. Those are hardly usable speeds, though.Just for the sake of completeness, I thought I should mention that latency between the three nodes are never more than 30ms, and I'll also include here some
iperf3measurements between the node that is receiving PUT object requests and the other two nodes:Since Garage wants to tolerate node failures, it will accept writes even if one node is unavailable. In that case, the data block will be propagated to that node when it comes back online. But crucially, the logic is the same whether the node is available or not: try to write the block to three nodes, and return ok as soon as two writes complete. So even if all three nodes are online, the third write is always asynchronous, although in general it terminates early enough so that not too much data gets buffered in RAM. (if the node is disconnected, Garage knows to just fail the transfer and not keep the data in RAM, so the issue is exacerbated in middle-ground cases: the node is available but with degraded bandwidth compared to the rest)
It's very strange that the RAM usage is high on all of the three nodes, there should be at least one node that has lower RAM usage. It's also strange that it does not decrease progressively over time as data is being transferred (although that could be explained by the networking scheduling algorihtm). The strangest thing is that it does not seem to decrease even after waiting for a long time. So I think that my explanation is not enough for what you are seeing, there has to be something else.
Can you check the network traffic between nodes, during the upload and after interrupting rclone? And also whether there is still network traffic a few minutes later, when you still see high RAM usage?
jnettopis a great tool to view the traffic going through active network connections. What would be interesting is if we could detect a scenario like this for example: buffering happens, RAM usage is high, there is some network traffic for some time, and at some point the network traffic stops and all RAM is freed. This would confirm my hypothesis. But if we see some other behavior like network traffic stopping entirely while RAM is still used, it has to be something else.The ram consumption is probably due to buffering, but given the good iperf benchmarks between your nodes (> 10 MiB/s for both links) this is not enough to explain the issue when limiting the rclone bandwidth to 10MiB/s.
Interesting. Thanks for the explanation!
I set out to run the tests you requested, and you're probably right that there are some network shenanigans going on, since I cannot now reproduce exactly the problem I saw earlier where all nodes would see a RAM spike and continue to sit at a high memory consumption even after the upload was aborted. I am certain I saw this several times before, though.
As of right now, what I'm seeing during the upload is more in line with what you were predicting:
10.10.10.10(500 Mbit/s link), the node receiving PUT requests, sees increasing RAM usage until OOM.10.10.10.12(200 Mbit/s link) climbs to about 300–500 MB RAM but no more.10.10.10.13(500 Mbit/s link) sits comfortably at 10–30 MB RAMAgain, the upload command is the following:
rclone copy mp3-dir garage:cld/mp3-dir --progress --fast-list --transfers 8During the upload, I ran the following
jnettopcommand on the PUT node, limiting the query to traffic on port 3901 over the Wireguard interface that connects the nodes (wg-mesh):$ sudo jnettop -i wg-mesh -x "port 3901" --display text -t 10 --format '$src$:$srcport$ $dst$:$dstport$ $totalbps$'Results:
Upload started, PUT node at < 100 MB RAM:
2 minutes in, 4 GB transfered, PUT node @ 1GB RAM:
Upload just aborted, RAM steadily declining on both nodes that saw an increase:
RAM back to < 20 MB after a minute or so:
Thanks, these results seem pretty consistent with what I was expecting.
Do you have an idea why Garage is not maxing out your network connection? Are your nodes running at 100% CPU all this time?
I think the fix will be on these two points:
add a mechanism to limit the number of data blocks that can be bufferred at any given time on the sending side
change the network scheduling algorithm to avoid excessive buffering on the receiving side
Oh, actually I read the units wrong, I thought it was bits and not bytes. If it is bytes then it looks like its maxing out your 200Mbps link which is nice.
~
The nodes are running a production Nomad cluster, but the average CPU usage on all of them is < 5%, so that can't be an issue. What makes you say Garage is not maxing out the network connections, though? Unless I'm misreading the results,jnettopsuggests30 MB/s (about the same transfer speed reported byrclone), and this does not seem that far off under the circumstances.EDIT: Nevermind, I typed this up before I saw your most recent comment.
lx referenced this issue2024-03-27 15:07:43 +00:00
@Cycneuramus Could you check if PR #792 fixes the issue? I can trigger a release build / docker image build on our CI if that's more practical for you.
Yes, that'd be much appreciated since I'd like to test it out in Nomad with the Docker driver.
Thanks. I'll give it a try tomorrow and report back.
The Docker image is
dxflrs/garage:85f580cbde4913fe8382316ff3c27b8443c61dd7I rebuilt my cluster from the ground up (using
lmdb) on the new Docker image. No dice, I'm afraid. I'm now back to the odd behavior I could observe on thesqlitebackend as well, where all nodes will gobble up memory and not release it even after the transfer is stopped.Here's what the memory curves look like during my upload test, the same one as before. The upload start/stop is probably apparent, and the peaks represent ~2 GB RAM:
PUT node, 500 Mbit/s:
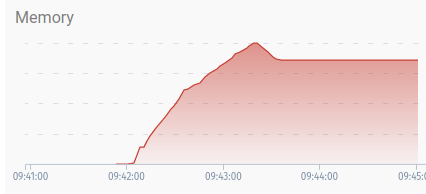
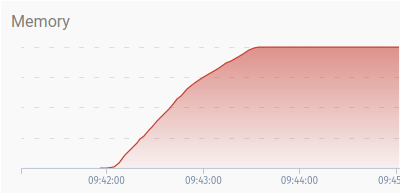
The 200 Mbit/s node:
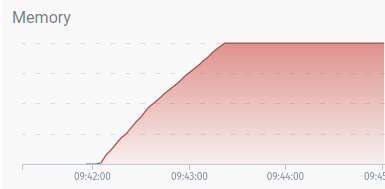
The 500 Mbit/s node:
Some stats from
sudo jnettop -i wg-mesh -x "port 3901" --display text -t 10 --format '$src$:$srcport$ $dst$:$dstport$ $totalbps$':Upload recently started, all nodes @ 1 GB RAM:
Upload stopped, all nodes @ 1,5–2 GB ram:
Minutes after stopped upload, all nodes still @ 1.5–2 GB RAM:
Even after 20 minutes, the memory usage have gone down by maybe a couple of hundred MBs but otherwise still holds around 1.5–2 GB on all nodes.
The only anomalies I could see in the log (though I'm not sure even this fits) were these sync messages spanning over ten seconds or so, on all nodes, a few minutes after the upload was stopped, and then again ~10 minutes later:
Output of
garage stats -aafter the upload test described above:I just observed, 30–40 minutes after the upload was stopped, the 200 Mbit/s node jumping back down to < 20 MB RAM over the course of 1 minute. The other nodes are still at 1.5–2 GB RAM though. The logs show nothing of note.
Thank you for your patience in trying to work this out.
Can you confirm that this memory is not just the memory map of LMDB's data file, but actual allocations made by Garage like buffer and stuff? The difference between the two is that LMDB's data file can easily be removed from RAM by the kernel, but it will only do so when the memory needs to be reclaimed for something else, whereas Garage's allocations cannot be reclaimed. Memory for the LMDB data file is counted by Nomad because it's hard to distinguish between the two, but it does not cause an OOM kill if it grows excessively.
Here are some tests you can do:
Can you try
cat /proc/<pid>/statuslike here? LMDB's memory appears under RssFile, whereas Garage's own allocations appear under RssAnon (if you are using the same Linux platform).Do your containers still get OOM killed if you let the transfer run longer?
Do you also have this with the sqlite backend?
lx referenced this issue2024-03-28 12:05:05 +00:00
Ah, sorry for introducing this ambiguity in my test. It appears your instinct was correct:
Actual RAM usage seems to sit between 300–400 MB during the course of the upload, with no OOM killing during the 10–15 minutes I let the upload run (before your fix, this would otherwise have happened way before that).
By the way, since the 200 Mbit/s node only has 6 GB RAM (whereas the other two have 32 GB / 24 GB), the
lmdbmemory behaviour you describe seems consistent with what I observed before about the 200 Mbit/s node suddenly going from ~2 GB RAM to 20 MB while the other two did not.In any case, I rebuilt the cluster on
sqliteagain, with pretty much the same results—though, curiously, the RAM usage reported by Nomad is still through the roof as in the case oflmdb, but since I don't know the inner workings of the DB engines, perhaps this is to be expected. In actual practice, though:So it seems your fix is working. I'll go ahead and actually try to use this thing now and see how it goes.
Nicely done, and thanks for your help!
lx referenced this issue2024-03-28 12:37:30 +00:00
Thanks, I'll let you close the issue then if you feel we've resolved the discussion.