Garage cluster encounters resync problems and does not seem to recover #911
Labels
No labels
action
check-aws
action
discussion-needed
action
for-external-contributors
action
for-newcomers
action
more-info-needed
action
need-funding
action
triage-required
kind
correctness
kind/experimental
kind
ideas
kind
improvement
kind
performance
kind
testing
kind
usability
kind
wrong-behavior
prio
critical
prio
low
scope
admin-api
scope
admin-sdk
scope
background-healing
scope
build
scope
documentation
scope
k8s
scope
layout
scope
metadata
scope
ops
scope
rpc
scope
s3-api
scope
security
scope
telemetry
No milestone
No project
No assignees
2 participants
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference: Deuxfleurs/garage#911
Loading…
Add table
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
We have a Garage cluster deployed in Kubernetes, consisting of 8 nodes with replication factor of 2. We had 6 nodes before, and as we added two more, we needed to do some shifting too so one node is in a different zone now.
Since we switched to 8 nodes there are lot of items in the resync queue and they do not seem to self heal. There are also many resync errors. Not sure how to proceed or what other information might be necessary.
Anyone has any idea what could be the problem ?
What is the version of garage you are using? Can you share what your garage status and layout look like? Can you also share the state of the works on a couple of nodes? Did you update the tranquility setting?
Items can be multiple time in the resync queue, so the absolute number of item in the resync queue is not necessarily indicative that nothing is happening.
garage stats:garage status:garage layout show:Not sure what to share exactly, we have logs and metrics in Grafana if that can help
As I see this would be a type of repair (related to scrubs), the only repair I tried was
garage repair --all-nodes --yes tables, run multiple times.@maximilien or anyone else: this is still an issue for us, the new nodes are still not serving traffic, any ideas what to do ?
Sorry I somehow missed your last message, can you share a screenshot of the garage grafana dashboard if you have it setup? I'm especially interested on the evolution of the "Resync queue length" and "Table GC queue length" graph, as well as the "rsync errored blocks".
How much bandwidth do you have between the sites?
So I have prepared the evolution of the 3 metrics asked (the period is from
2024-12-12 23:33:57 UTC +2to2025-01-08 23:05:08 UTC +2) :block_resync_queue_length) - we have multiple samples here to avoid the outlierstable_gc_todo_queue_length) - as I see there are multiple tables here, I have made a sum between them for now (we can be more granular if needed)block_resync_errored_blocks) - we have multiple samples here to avoid the outliersI have measured some samples and found the following:
I have made another screenshot for the metric
block_resync_queue_lengthwhere I change the period a bit to avoid the big outliers@Szetty can you give me the resync queue on garage node 6 and 7 between dec 18th and today? With the Y axis scaled to the graph (not set at zero, I want to see the variations). But my initial estimate is simply that the cluster is syncing, very slowly, due to the amount of data you have, which (assuming you have only garage data on the disks) seems to be in the order of 10TB or more per zone, and relatively slow networking, not even GB.
So the answer is to wait. Given the amount of blocks that need to be moved and the bandwidth you got, it could take several weeks for garage to sync. I also see that you are running Garage 1.0.0, I suggest you consider upgrading to 1.0.1 later.
What we can do to increase the resync speed (at the cost of performance for serving actual requests) is to tweak the tranquility. Can you execute into one of node 6 or 7 and do a
/garage worker get? (there is no back so you have to exec the command right away).You should get an output like this one
Depending on your values, you might then want to lower the
resync-tranquilitysetting, 1 would be a good value, otherwise you can try to go to zero, while watching your application and system metrics to see what the impact is. Depending on your CPU, memory and system resources you can also adjustresync-worker-count, although usually we advise to set it to the number of CPU available.To set the value you can use
/garage worker set resync-tranquility <0-n>and/garage worker set resync-worker-count <0-n>. Those settings are local to the node so you'll need to run those commands one node 6 and 7 separately.I have attached the resync queue for garage-6 and garage-7 between the requested time: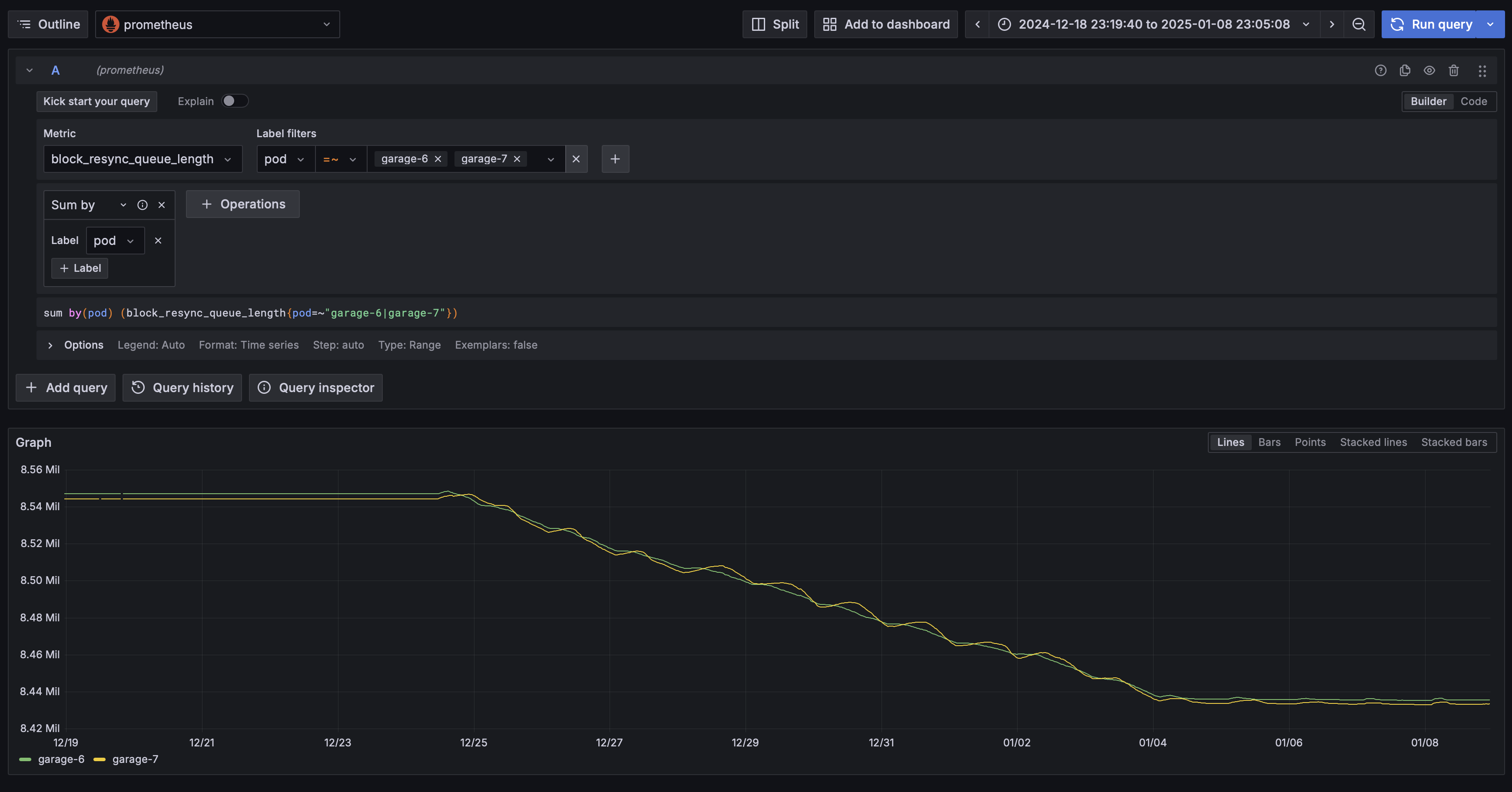
I have run
/garage worker geton garage-6:and garage-7:
Couple of questions about the improvements:
1.0.1help in this sense ? if yes, how ?resync-tranquilitydo ?resync-worker-counttoo ?I have been looking through the logs a bit, and found these when starting garage-6: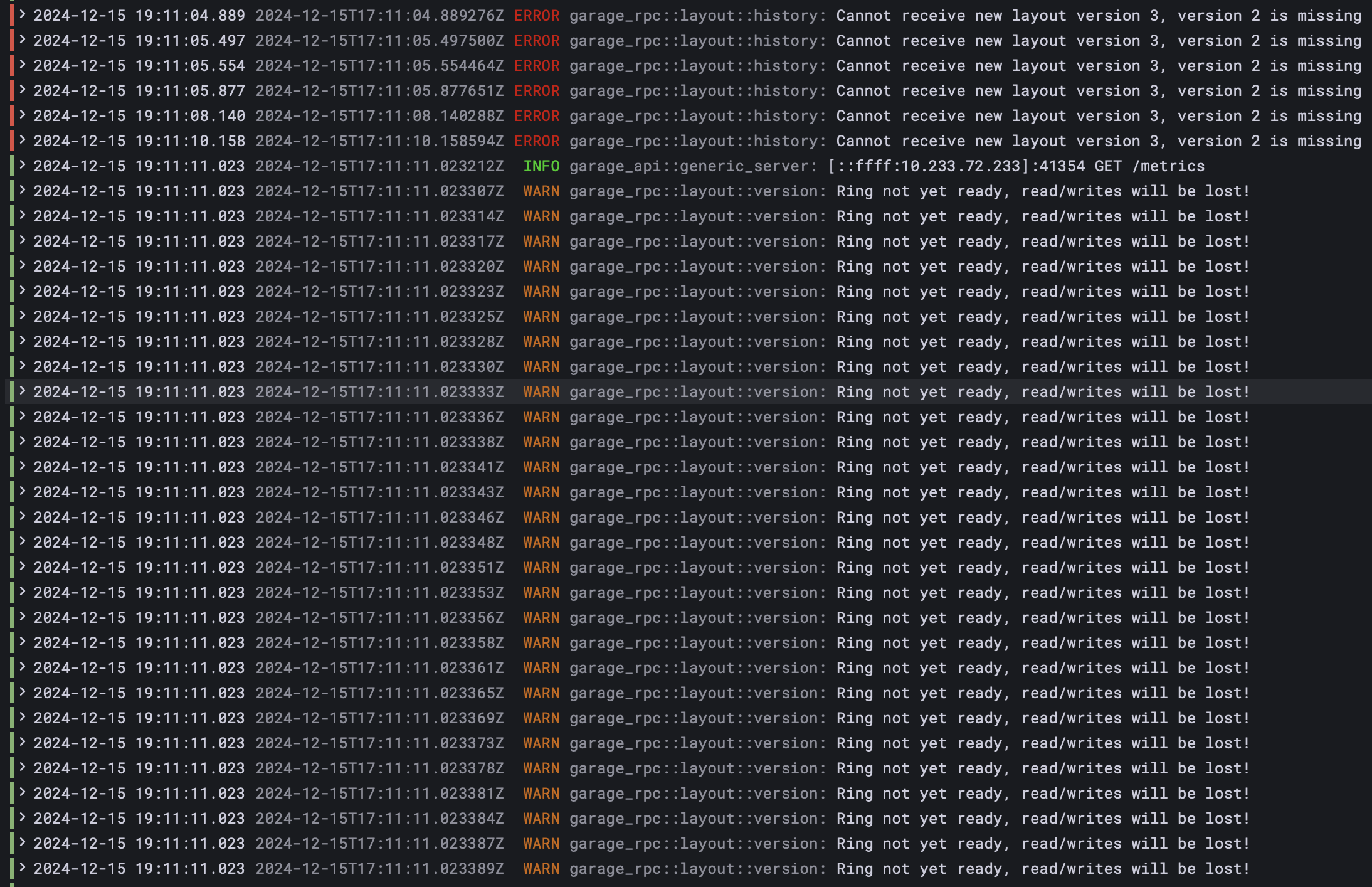
the warnings about the ring are still present on both garage-6 and garage-7, anything to worry about ?
Garage 1.0.1 will definitely help with the layout issue you quoted above, an maybe as well with metadata performance depending on how much memory you have and how big your LMDB database is. So please do upgrade first, especially if you have a backup of the data in this cluster already.
The tranquility factor cause garage to "sleep" for a certain duration between tasks. From my understanding (and @trinity-1686a can maybe correct me here), if resyncing a block takes 1s in average and you have a tranquility factor of 2, then garage will sleep 2s between each sync.
I suggest you start by lowering the tranquility to 1 and set the worker count to 2 on both nodes, and tale a look at how the resync queue evolves. You can likely keep your current CPU allocation, just take a look at how the CPU usage evolves.
I don't believe re-ingesting everything will be necessarily faster, as you'll also have to write the blocks to the other nodes, which seem to be fine for now.
okay, seems like it is coming around now; upgrading the version and making the changes to tranquility and worker count seem helpful. Thank you for your patience and for the help :)
You're welcome, glad we got yourself out of this!