Inconsistency error "Bucket doesn't have other aliases, please delete it instead of just unaliasing" when deleting some buckets #988
Labels
No labels
action
check-aws
action
discussion-needed
action
for-external-contributors
action
for-newcomers
action
more-info-needed
action
need-funding
action
triage-required
kind
correctness
kind/experimental
kind
ideas
kind
improvement
kind
performance
kind
testing
kind
usability
kind
wrong-behavior
prio
critical
prio
low
scope
admin-api
scope
admin-sdk
scope
background-healing
scope
build
scope
documentation
scope
k8s
scope
layout
scope
metadata
scope
ops
scope
rpc
scope
s3-api
scope
security
scope
telemetry
No milestone
No project
No assignees
3 participants
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference: Deuxfleurs/garage#988
Loading…
Add table
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Garage version:
1.0.1DB engine:
LMDBLayout: cluster with 3 nodes
Sometimes when trying to delete some buckets via S3 Client I'm getting this error:
ERROR: S3 error: 400 (InvalidRequest): Bad request: Bucket <bucket_name> doesn't have other aliases, please delete it instead of just unaliasing.Which doesn't make any sense, since according to https://git.deuxfleurs.fr/Deuxfleurs/garage/src/branch/main/src/api/s3/bucket.rs#L200 Garage checks if the bucket has other aliases and only then calls the unaliasing method. Then another alias check happens, which somehow returns different result.
If I try to delete such buckets via Admin API, I'm getting another error:
Internal error: Bucket <bucket_id> does not have alias <bucket_name> in namespace of key <key_id>I've investigated buckets with this problem via Admin API and it seems like they state is inconsistent. If I'm listing all the buckets by the key with
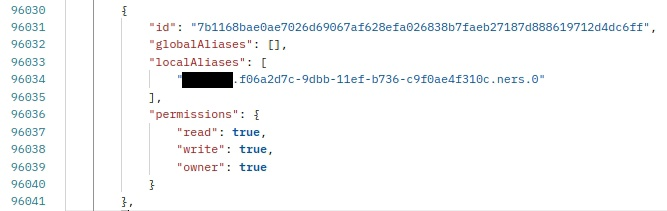
/v1/key?id=<key_id>, I see the local alias:However, if I request this bucket's info with
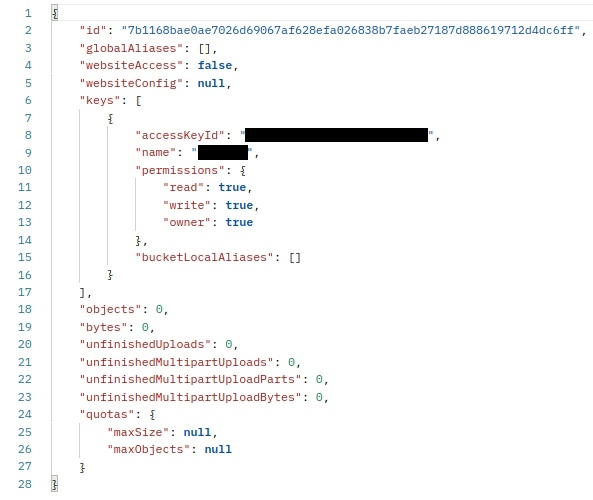
/v1/bucket?id=<bucket_id>, I see no aliases at all:I'm not exactly sure if this is causing problem with bucket deleting, but it's very likely since exactly such buckets can't be deleted. And it seems wrong anyway.
We have tried to run full Garage synchronization in order to fix this inconsistency, but problem still there.
Unfortunately, I'm unable to provide reproducible steps as this problem seems completely random. Our app creating many buckets via S3 Client and seems like some of them (every 10-15, I guess? very approximately) already appears in such broken state, however the rest of them completely ok.
It would be great if you could explain or investigate it somehow, but really any help and hints would be highly appreciated. Right now we have no mechanism whatsoever to delete this problem buckets and it affects our project, so I need some directions. What can be done to reproduce this problem or at least to get more info? Enable some extended logging? Run some another repair mechanism?
It also would be good to be able to access Garage database directly - to actually see the problem in concrete tables at least. But our DevOps engineer told me that Garage creates DB data completely under the hood and doesn't expose any credentials, so direct access is impossible, even read-only. Is that true? Can I somehow connect to LMDB that Garage using?
Hello, thank you for the detailed bug report.
First of all, sorry that Garage is displaying such inconsistent behavior and causing you issues.
To better understand what is going on here: Garage's metadata storage is unnormalized, meaning that the same information can be present at different locations, and these locations must be kept in sync. This is a consequence of the NoSQL-like architecture we have chosen. The information about bucket aliases is kept in two locations: one copy in the bucket table (each bucket knows what its aliases are), and one copy in either a global alias table for global aliases, or in the access key table for local aliases (access keys know what aliases they have to buckets, which allows us to find buckets rapidly when answering requests). In your case, these two locations have fallen out of sync: in the bucket table, the local alias is present, whereas in the key table, it is absent. I think the consequence is that the check at line 213 concludes that you are deleting a global alias, whereas you are in fact deleting a local alias, and then the whole logic fails. I think this check should probably also be deleted entirely.
I cannot say precisely how/why the two tables have fallen out of sync (see #147, #649, a partial "fix" in #723 and discussion on our blog) and why this happens regularly in your cluster, however it is clear that we must improve resilience to such inconsistent states, as it is proably not possible to fully prevent them from the start, at least without rethinking our design in a pretty fundamental way.
For now, what I can do is write a quick patch and provide you with a Garage version that should be able to delete the bucket successfully.
Medium-term, such inconsistencies should be detected and repaired automatically, under the following principle: when information is stored in two places due to denormalization, one place should be authoritative so that the other one can be updated when an inconsistency is detected.
Concerning direct access to Garage's metadata DB, it's indeed quite hard to do because LMDB proves just a very basic key-value store and we are using it in a very custom way. It's not as simple as opening an SQL database, and trying to modify it outside of the Garage binary will for sure cause issues, but if you want to inspect what is going on you can at least write a small program try to open it in read-only mode using the LMDB library. Most data is stored in the messagepack format, sometimes with a small header of a few bytes that indicates the version of garage, so it should be quite doable to get a print-out of the data that is stored.
Another thing you can do to try fixing the inconsistency is creating the local alias again before deleting the bucket (with the LocalAliasBucket admin API call). In theory, this should make it exist in both locations (bucket table and key table), which will then allow the DeleteBucket call to complete successfully.
Hi @lx
Thank you for such quick response and clarification! I started working with Garage only recently, so your details about internal work was very valuable.
Am I understood correctly, currently there is no mechanism that could automatically repair this kind of inconsistency and it need to be implemented yet, as you described in "mid-term" section?
Quick patch on bucket deleting would be great! Ideally if it could fix deleting via S3 Client specifically, so we don't have to manually delete problematic buckets via REST API.
About DB - understood. Manually modifying it not an option of course, just wanted to peek into it in read-only for better understanding of what's going on, but since you already confirmed my thoughts, I think database access isn't necessary.
@nkozhevnikov could you try either one of the two solutions:
940988e484ee8ecbc397654716ed9926bea0fc5d, which should be available both as a Docker image and as a static binary in the "development builds" section of the download page. I don't guarantee that deleting buckets in an inconsistent state through the S3 API will be fixed, but at least through the admin API it should work@lx okay, thanks for the new quick build, I would like to try the second option. Give me some time to update our Garage via DevOps and I'll come back with feedback. If there will be some problems, I'll try first solution.
I just realized, I assume new build was made from the last Garage v1.1.0? If so, we will need more time, since minor update more complex for us than just patch and was planned only at the end of the week. So I can test new build only next week.
In the meantime, I've tried your first solution - to add local alias to problematic bucket manually via admin API. Unfortunately, got error
Bad request: Alias <bucket_name> already exists in namespace of key <key_id> and points to different bucket: cbd15a10bc56364fAs I found out, this strange bucket id was trimmed for some reason and actually means normal id
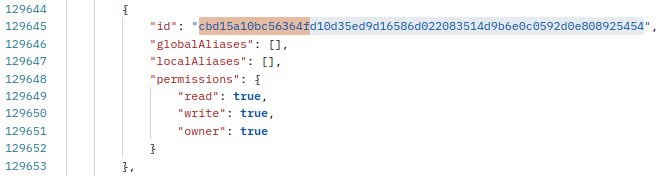
cbd15a10bc56364fd10d35ed9d16586d022083514d9b6e0c0592d0e808925454, as I was able to find it in general list of this key's buckets. And there is reverse problem, this bucket has no alias in the list:But have it in the bucket info:
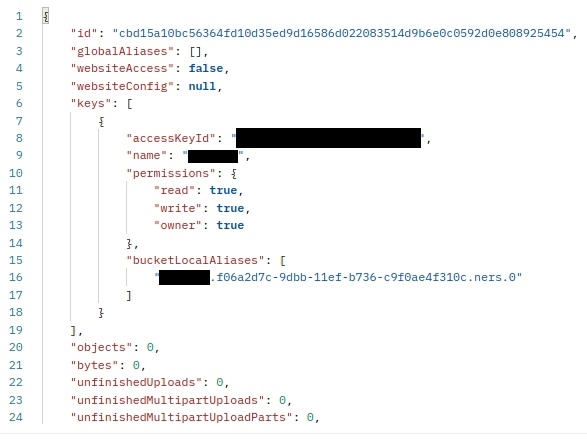
I've successfully deleted this bucket via admin API (by "new" id) and then tried to delete initial problematic bucket, but got the same error about alias. Then I've tried to add local alias again, but strangely, got the same error about
points to different bucket: cbd15a10bc56364f. But if I'm trying to get bucket info about idcbd15a10bc56364fd10d35ed9d16586d022083514d9b6e0c0592d0e808925454, I'm getting "Bucket not found" error. In general bucket list this id also doesn't appear anymore.So bucket was deleted, but method that adds local alias thinks that it was not.
There is also a thing I didn't mention initially, but now I think it can be important. According to the method listing all key's buckets, we have huge amount of buckets without aliases at all:

Also, most of this buckets, when picked randomly, doesn't contain any aliases both in the general list and in the bucket info. And since we are creating buckets only from our app, via S3 client, I thought all of these was from somewhere else, maybe some kind of internal Garage thing or something like that, since you shouldn't get such buckets if creating them normally via S3 client.
We have, like, several tens of thousands buckets according to the general list and with naked eye it seems like the absolute majority of buckets are like that. But according to my previous comment, some of them, apparently, could contain local aliases, which may be part of the problem.
@lx any thoughts? Are our consistency completely messed up or this is kinda normal?
The issue you are having is probably being exacerbated by calling
CreateBucketsimultaneously from several places at once (or in a small time period), with the same bucket name + access key. In that case, you would be hitting #649 all the time, which would explain what we are seeing. Untill #649 is resolved, to avoid creating many inconsistent buckets, you should avoid callingCreateBucketwithout coordination. Ideally, you would add an external coordination mechanism to ensure that there is only one call toCreateBucketfor each bucket name + access key.To answer your question, this is "normal" in the sense that it's the consequence of a limitation of Garage, but it's obviously a bug and not desirable behavior.
For now, I will try to write a small repair procedure to restore consistency between buckets and aliases, and provide you with a new build so that you can run it. Of course this will not fix the root cause, but at least it will help you restoring your cluster back to a clean state.
@lx would directing all create bucket calls to a single node alleviate somewhat that effect?
@nkozhevnikov I have made a new build
d067cfef22e59b65b3fbde7fde2dd40deca1a15ethat includes a newgarage repair aliasescommand to fix inconsistencies like the ones you are having. If you'd like to try it out, please use the following procedure for maximum safety:garage repair -a --yes tables, and wait for the table resync to finish (you can check this in the logs).garage meta snapshot -aRUST_LOG=garage=debugenvironment variable so that we can get more data about what the repair command is doing.garage repair --yes aliaseson a single Garage node. If you get to this step, please save the logs of you Garage daemon during this operation and upload them here.@lx okay, thanks for the clarification about
CreateBucket. I already figured out that problem can be in the bucket creation and added the simplest fix with small throttling when our app creating many buckets in a row. Still need investigate all places with bucket creation and maybe indeed add some coordination system, though. Will see.About new command - great, really appreciate it! I handed over the instructions to our DevOps engineer, we are planning to update Garage and to repair cluster tomorrow. So I'll try to check the cluster state and upload logs for you at the beginning of next week.
@lx hello, we have successfully updated Garage and done everything according to your instructions. After that I was able to delete all problematic buckets, thanks to your new repair command. I was deleting them via Admin API, couldn't check S3 client because ran out of broken examples.
We don't have many elaborate ways to create buckets, so apparently simple throttling in the place of bucket creation did the job - AFAIK we didn't have single broken bucket since that fix.
So, for now, it seems like we don't have any more problems with Garage, aside for many empty buckets without aliases at all, but I guess we have to just delete them all manually. Anyway, I don't think they cause any problems to our work.
There is our logs as you requested: