Garage resync queue length just grows #934
Labels
No labels
action
check-aws
action
discussion-needed
action
for-external-contributors
action
for-newcomers
action
more-info-needed
action
need-funding
action
triage-required
kind
correctness
kind/experimental
kind
ideas
kind
improvement
kind
performance
kind
testing
kind
usability
kind
wrong-behavior
prio
critical
prio
low
scope
admin-api
scope
admin-sdk
scope
background-healing
scope
build
scope
documentation
scope
k8s
scope
layout
scope
metadata
scope
ops
scope
rpc
scope
s3-api
scope
security
scope
telemetry
No milestone
No project
No assignees
3 participants
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference: Deuxfleurs/garage#934
Loading…
Add table
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Hello again,
I am back with a similar problem as before, but a slightly different behaviour. While the last problem was mostly related to new nodes, and resync not being fast enough, now these are probably not the problem; we did not change our Garage cluster at all, and I left the resync settings that were used to fix the previous problem (will show the settings below).
First of all an overview of all metrics: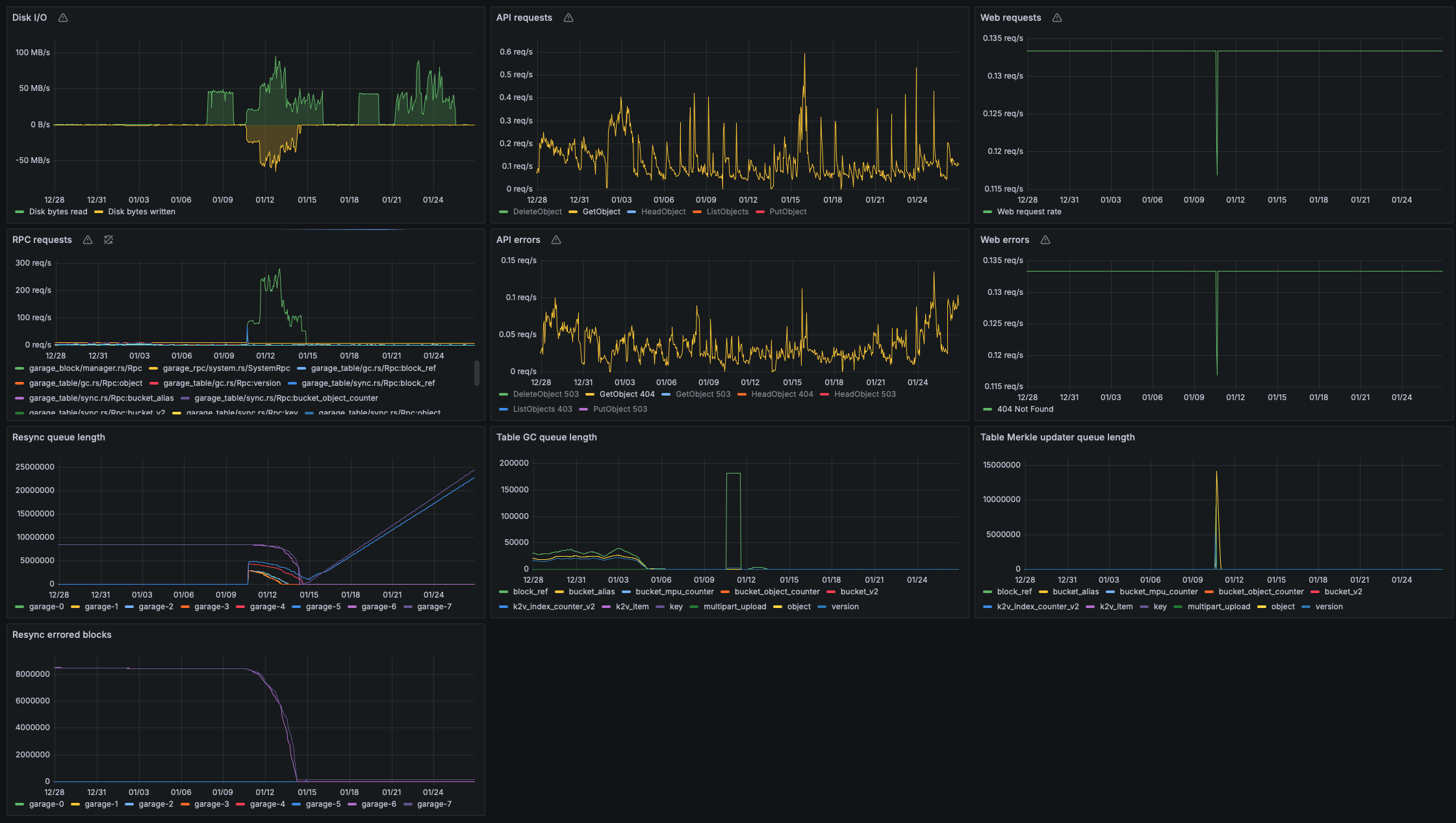
We can observe that our previous problem mostly finished on 14th of January and it seems that data was synchronized correctly because all nodes now have similar free disk space (while the new ones started at ~7 TB and the old ones were reaching exhaustion, barely surviving at 100 GB and often being taken out of commission by k8s due to low disk size).
Not long after a new problem started, not sure why though: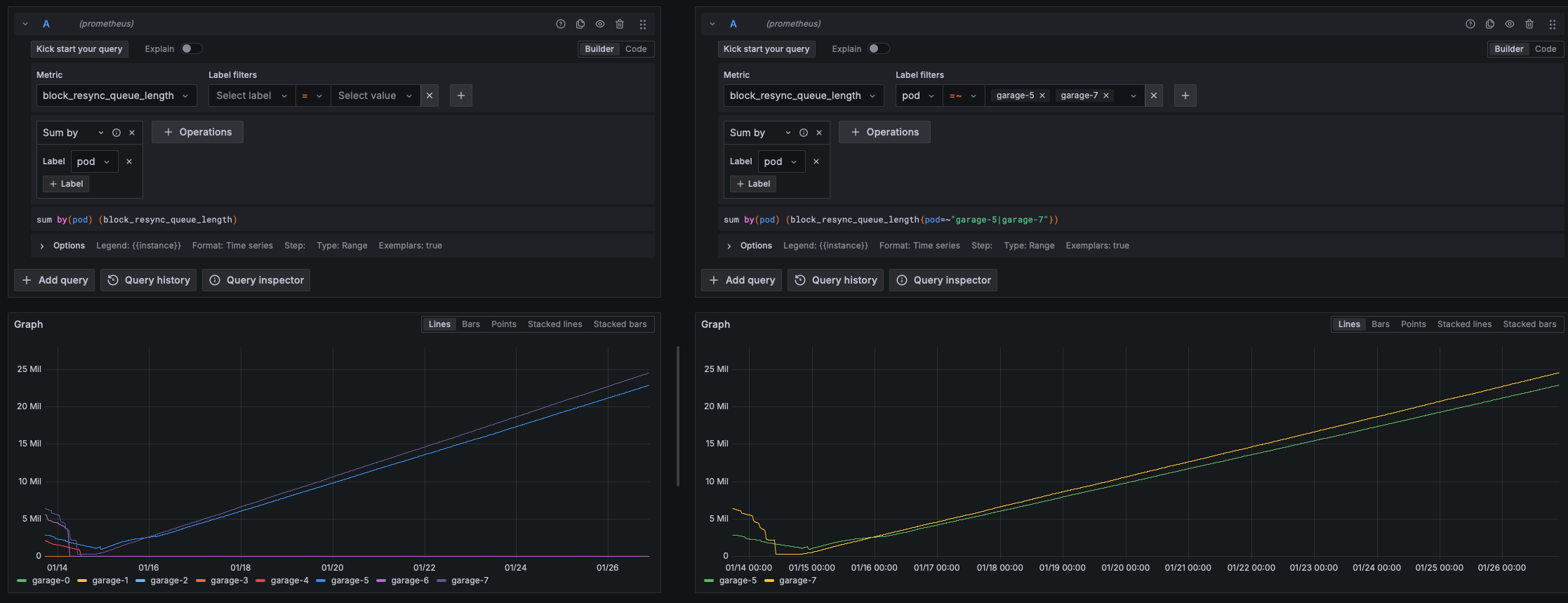
Worker settings on the nodes:
Stats as seen from garage-5:
Any ideas what could be going on ? Do you need any more information ?
Thank you.
With respect,
Arnold
Maybe taking a look at the logs on those nodes would be interesting. I suspect they maybe have some kind of connectivity issue that prevent garage from syncing blocks from other nodes and causing the resync queue to blow up.
Closing this for now, please reopen it if needed
Finally had time to check logs, the problem is still going on and the resync queue is just growing bigger and bigger.
So for the two nodes where we have problems (garage-5 and garage-7) I will provide an error log volume to show when and how errors started and then a snapshot of all logs (info, warn and error) on both when the errors started.
For garage-5: garage-5 logs when errors started.txt and
For garage-7: garage-7 logs when errors started.txt and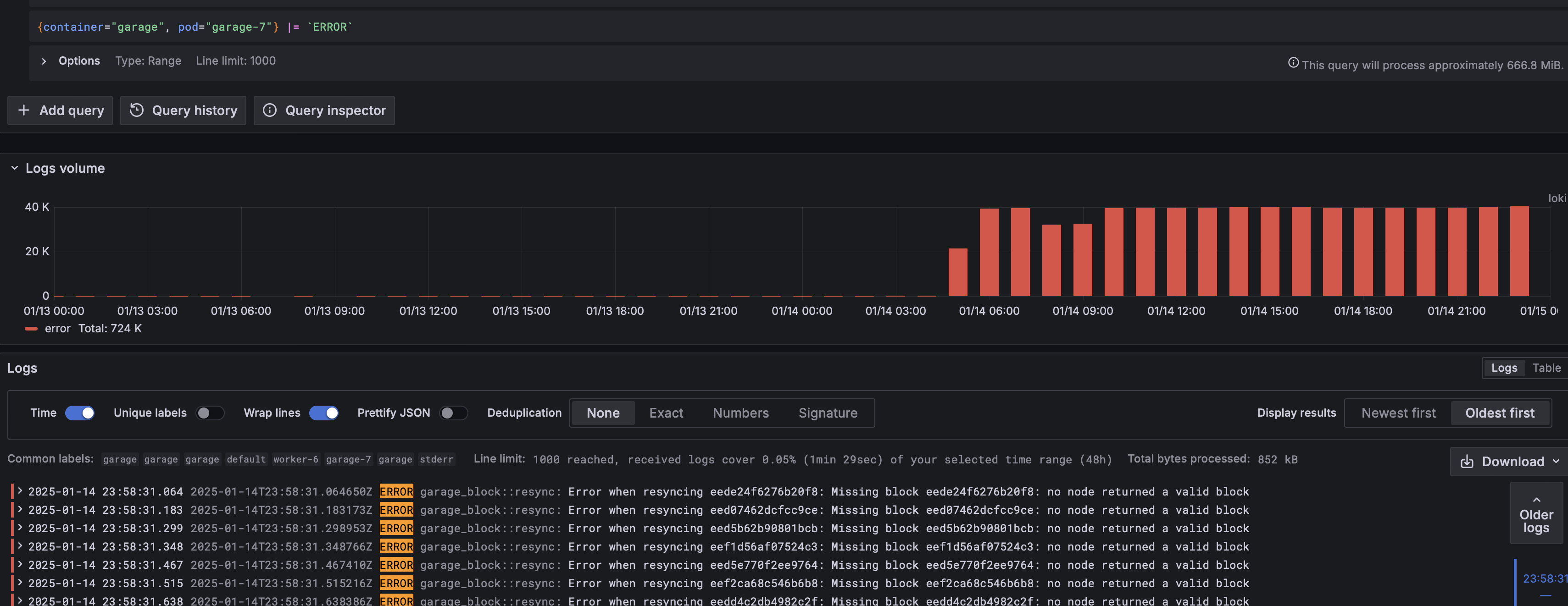
Please tell me if you need more information or how to investigate next. Thank you.
@maximilien any ideas ?
@maximilien any updates ?
Just came back from travel. Your last set of screenshots confirm what the resync queue is showing: those nodes don't seem to be able to get those blocks anywhere, or they have a corrupted refcount. Can you provide the layout of the cluster? What's the replication count? You can use
garage layout show.I'm also worried that in the current situation your resync queue is going to blow up. Can you provide updates data/screenshot to see how it evolved? I'm specifically interested in recent numbers and not necessarily the past. Having the last 7 days should be enough.
As a sanity check, could you also provide the output of
garage block info 072285974ac26607. The block ID is from the garage-5 log lines:The idea here would be to validate if:
This should allow us to narrow down the issue.
kubectl exec --stdin --tty garage-5 -- /garage layout show
kubectl exec --stdin --tty garage-5 -- /garage stats
Only garage-5 and garage-7 (the two problematic nodes) have the block:
kubectl exec --stdin --tty garage-7 -- /garage block info 072285974ac26607
Evolution of resync queue size for last 7 days:
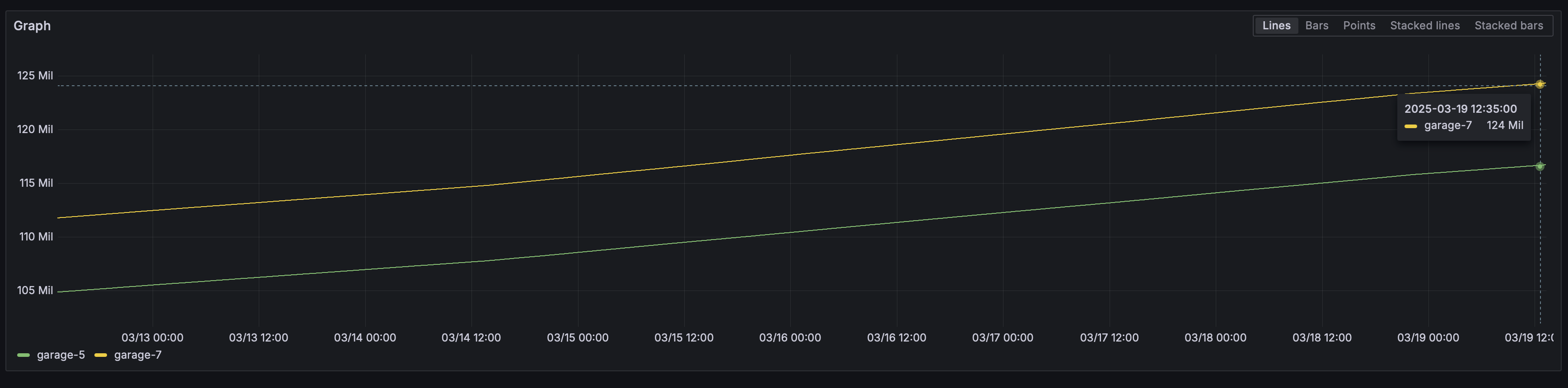
Could you post the output of
garage layout historyas well?@lx wrote in #934 (comment):
sure
kubectl exec --stdin --tty garage-5 -- /garage layout history
Concerning this output:
It seems to indicate that block
0722...belongs to an live object, currently stored in your cluster. The fact that your Garage node cannot fetch it from other nodes might mean that it is entirely absent from the cluster, but it could also just be that the file is somewhere where Garage is not able to find it.Can you check:
f2f262764aa36e1d83be89c4893413b492ea3fed3769e69cfceba699e3ef96dcin bucket whose full ID starts with34ffe40ab52d0c24)072285974ac26607244181aff8b3e6989e85b43626e699249b4efe961190be63can be found in a data directory of any node of your cluster? It should be in<data_dir>/07/22/, and it possibly has a.zstextension if you have compression enabled.Moreover, do you have any Garage node that is configured to use multiple data directories ?
If the answer to question 1 is that the object no longer exists in the bucket, or that the current version is not version
b290a580cf0953b7but a newer version, you might just be in the case of an internal inconsistency where versionb290a580cf0953b7has not properly been marked as deleted, even though it is no longer the current version of the object.To fix such inconsistencies, please run the following two repair procedures:
Note that these repair procedures take a long time to run (you can watch them using
garage worker list/garage worker info), and they are interrupted and not restarted automatically if your Garage daemon restarts. So to ensure that they run to completion, check that your Garage daemons are not restarted by k8s, and monitor the logs for any message indicating completion of the repair procedure.Not entirely sure how to do this, I tried head_object, with the right bucket, but not sure what to put as object_path, if the key
f2f262764aa36e1d83be89c4893413b492ea3fed3769e69cfceba699e3ef96dcis the entire object path, it returns 404I have found the folder on 4 nodes, 2 of them are empty, and 2 of them have many files, but not
072285974ac26607244181aff8b3e6989e85b43626e699249b4efe961190be63.zstDid not know about "Multi-HDD support" until now, so if it is not the default, I am pretty sure it is not enabled
I think I know what happened, I forgot about this, but at some point when we were very low on disk size, I have deleted some folders directly from the disk, thinking that it would be rewritten as we use Garage for backup, maybe this messed up some internal tracking of the data, any idea how to synchronize the metadata based on the data ?
Ok, I think launching the two repair procedures I mentioned above and giving them enough time to finish should fix your issue.
Ok, I have launched the two repair procedures, and they seem to be finished, but issue is still there, will leave you seem console output to see.
❯ kubectl exec --stdin --tty garage-5 -- /garage repair -a --yes block-refs
❯ kubectl exec --stdin --tty garage-5 -- /garage repair -a --yes versions
Then a bit later:
❯ kubectl exec --stdin --tty garage-5 -- /garage worker info 55
❯ kubectl exec --stdin --tty garage-5 -- /garage worker info 56
@maximilien @lx any more ideas ?
@Szetty I'd say we are in either of two cases:
To test hypothesis 1, you could try wiping the db from one of your two nodes so that it will be rebuilt from the cluster, and see if that fixes the issue. The procedure would be something like:
db.lmdbin the metadata directory to a separate locationdb.lmdbin the metadata directory (do not remove other files such ascluster_layout,node_id, etc)garage statusand that its role has not changedIf that does not fix the issue, that probably means that you are in case 2 and some data files could have been lost. In that case, we would have to look for evidence that some of your objects are indeed unreadable due to missing data blocks, which we don't have at the moment.
okay, so I have tried the first option, and it seems that it is not solving the issue, I will attach the resync queue size and the resync error blocks count. The errors are back to the value before, and the queue is steadily growing too.
Resync errors: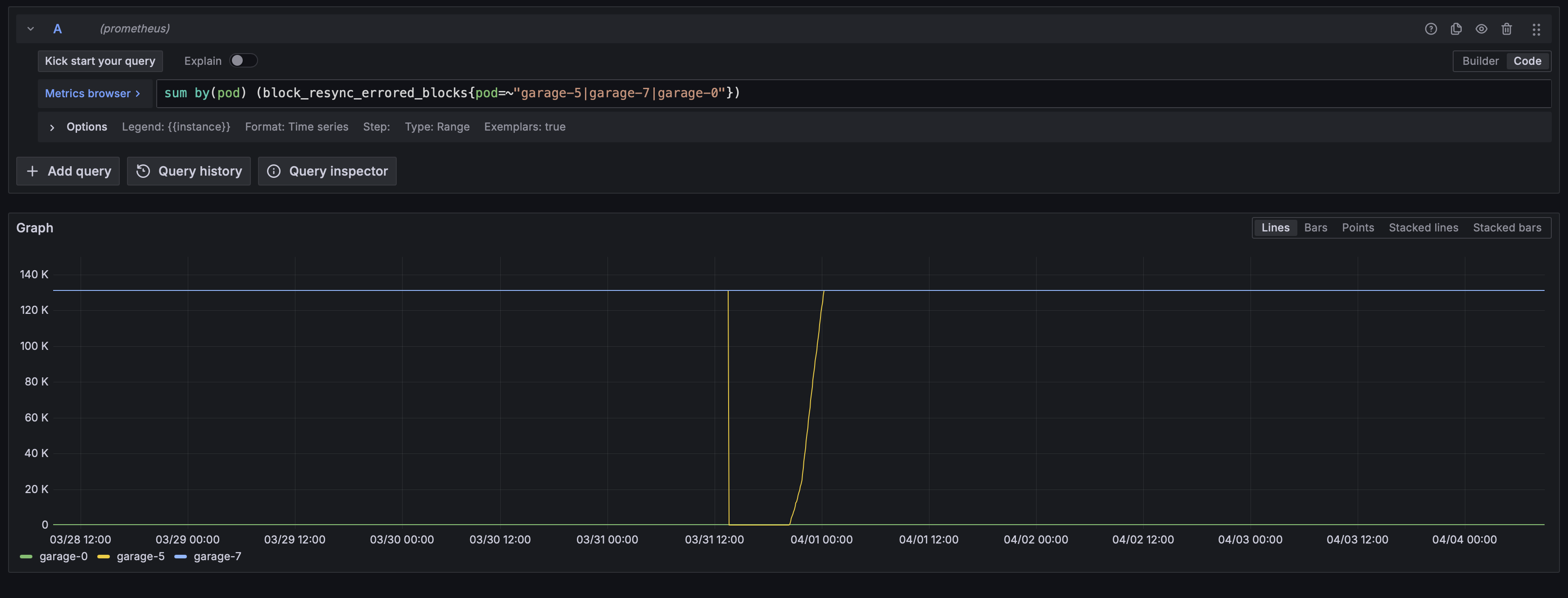
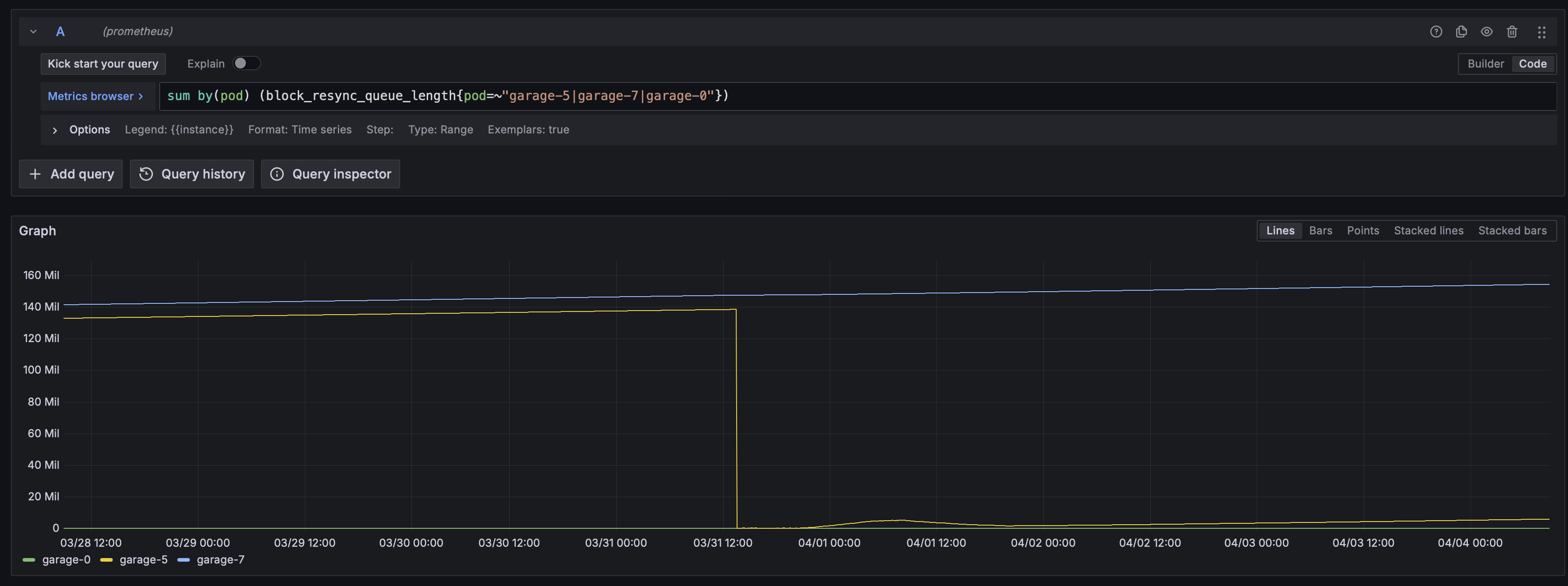
Resync queue:
@maximilien @lx what should we do next ?
If you are certain that the missing blocks do not correspond to objects stored in the cluster that you or your users might one day want to access, you may use
garage block purgeto inform Garage that those blocks are not needed anymore and that it can safely skip resyncing them. Usegarage block list-errorsto fetch the list of blocks in an error state, and feed that list as an argument intogarage block purge.If you do so, please report the output of
garage block purge("purged x blocks, x versions, x objects, etc")