3.6 KiB
Benchmarks
With Garage, we wanted to build a software defined storage service that follow the KISS principle, that is suitable for geo-distributed deployments and more generally that would work well for community hosting (like a Mastodon instance).
In our benchmarks, we aim to quantify how Garage performs on these goals compared to the other available solutions.
Geo-distribution
The main challenge in a geo-distributed setup is latency between nodes of the cluster. The more a user request will require intra-cluster requests to complete, the more its latency will increase. This is especially true for sequential requests: requests that must wait the result of another request to be sent. We designed Garage without consensus algorithms (eg. Paxos or Raft) to minimize the number of sequential and parallel requests.
This serie of benchmarks quantifies the impact of this design choice.
On a simple simulated network
We start with a controlled environment, all the instances are running on the same (powerful enough) machine.
To control the network latency, we simulate the network with mknet (a tool we developped, based on tc and the linux network stack).
To mesure S3 endpoints latency, we use our own tool s3lat to observe only the intra-cluster latency and not some contention on the nodes (CPU, RAM, disk I/O, network bandwidth, etc.).
Compared to other benchmark tools, S3Lat sends only one (small) request at the same time and measures its latency.
We selected 5 standard endpoints that are often in the critical path: ListBuckets, ListObjects, GetObject, PutObject and RemoveObject.
In this first benchmark, we consider 5 instances that are located in a different place each. To simulate the distance, we configure mknet with a RTT between each node of 100 ms +/- 20 ms of jitter. We get the following graph, where the colored bars represent the mean latency while the error bars the minimum and maximum one:
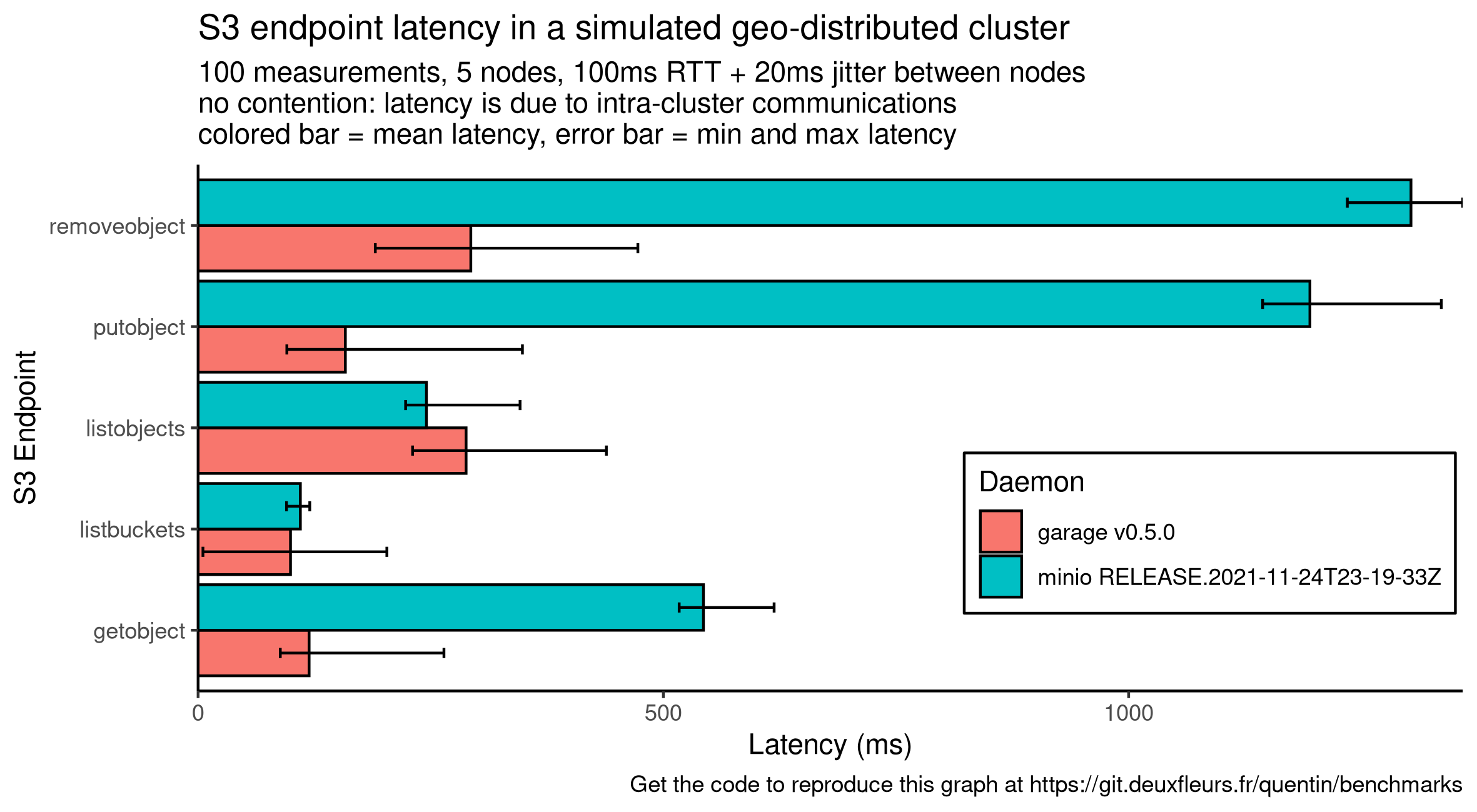
Compared to garage, minio latency drastically increases on 3 endpoints: GetObject, PutObject, RemoveObject.
We suppose that these requests on minio make transactions over Raft, involving 4 sequential requests: 1) sending the message to the leader, 2) having the leader dispatch it to the other nodes, 3) waiting for the confirmation of followers and finally 4) commiting it. With our current configuration, one Raft transaction will take around 400 ms. GetObject seems to correlate to 1 transaction while PutObject and RemoveObject seems to correlate to 2 or 3. Reviewing minio code would be required to confirm this hypothesis.
Conversely, garage uses an architecture similar to DynamoDB and never require global cluster coordination to answer a request. Instead, garage can always contact the right node in charge of the requested data, and can answer in as low as one request in the case of GetObject and PutObject. We also observed that Garage latency, while often lower to minio, is more dispersed: garage is still in beta and has not received any performance optimization yet.
On a complex simulated network
TODO
On a real world deployment
TODO
Performance stability
A storage cluster will encounter different scenario over its life, many of them will not be predictable. In this context, we argue that, more than peak performances, we should seek predictable and stable performances to ensure data availability.
Reference
TODO
On a degraded cluster
TODO
At scale
TODO